Understanding the Basics of Working in a Garbage-Collected Platform
Every program uses resources of one sort or another, be they files, memory buffers, screen space, network connections, database resources, and so on.
In fact, in an object-oriented environment, every type identifies some resource available for a program’s use.
To use any of these resources requires memory to be allocated to represent the type. The following steps are required to access a resource:
Allocate memory for the type that represents the resource by calling the intermediate language’s newobj instruction, which is emitted when you use the new operator in C#.
Initialize the memory to set the initial state of the resource and to make the resource usable. The type’s instance constructor is responsible for setting this initial state.
Use the resource by accessing the type’s members (repeating as necessary).
Tear down(vt. 向 猛扑,冲下; 拆毁,拆卸) the state of a resource to clean up. I’ll address this topic in the section “The Dispose Pattern: Forcing an Object to Clean Up” later in this chapter.
Free the memory. The garbage collector is solely responsible for this step.
This seemingly simple paradigm has been one of the major sources of programming errors.
How many times have programmers forgotten to free memory when it is no longer needed?
How many times have programmers attempted to use memory after it had already been freed?
With unmanaged programming, these two application bugs are worse than most others because you usually can’t predict the consequences or the timing of them.
For other bugs, when you see your application misbehaving, you just fix the problem.
But these two bugs cause resource leaks (memory consumption) and object corruption (destabilization), making the application perform unpredictably.
In fact, there are many tools (such as the Microsoft Windows Task Manager, the System Monitor ActiveX Control, NuMega BoundsChecker from Compuware, and Rational’s Purify) that are specifically designed to help developers locate these types of bugs.
Proper resource management is very difficult and quite tedious(adj. 单调沉闷的; 冗长乏味的; 令人生厌的).
It distracts developers from concentrating on the real problems that they’re trying to solve.
It would be wonderful if some mechanism existed that simplified the mind-numbing(adj. (糟糕、无聊或程度强烈到)令人头脑麻木的) memory-management task for developers.
Fortunately, there is: Garbage Collection.
Garbage collection completely absolves the developer from having to track memory usage and know when to free memory.
However, the garbage collector doesn’t know anything about the resource represented by the type in memory, which means that a garbage collector can’t know how to perform Step 4 in the preceding list:
tear down the state of a resource to clean up.
To get a resource to clean up properly, the developer must write code that knows how to properly clean up a resource.
The developer writes this code in the Finalize, Dispose, and Close methods, as described later in this chapter.
However, as you’ll see, the garbage collector can offer some assistance here too, allowing developers to skip Step 4 in many circumstances.
Also, most types, including String, Attribute, Delegate, and Exception, represent resources that don’t require any special cleanup.
For example, a String resource can be completely cleaned up simply by destroying the character array maintained in the object’s memory.
On the other hand, a type that represents (or wraps) an unmanaged or native resource, such as a file, a database connection, a socket, a mutex, a bitmap, an icon, and so on, always requires the execution of some cleanup code when the object is about to have its memory reclaimed.
In this chapter, I’ll explain how to properly define types that require explicit clean up, and I’ll show you how to properly use types that offer this explicit clean-up.
For now, let’s examine how memory is allocated and how resources are initialized.
Allocating Resources from the Managed Heap
The CLR requires that all resources to be allocated from a heap called the managed heap.
This heap is similar to a C-runtime heap, except that you never delete objects from the managed heap.
Objects are automatically deleted when the application no longer needs them.
This, of course, raises the que stion, “How does the managed heap know when the application is no longer using an object?” I’ll address this question shortly.
Several garbage-collection algorithms are in use today.
Each algorithm is fine-tuned for a particular environment to provide the best performance.
In this chapter, I’ll concentrate on the garbage-collection algorithm used by the Microsoft .NET Framework’s CLR.
Let’s start off with the basic concepts.
When a process is initialized, the CLR reserves a contiguous region of address space that initially contains no backing storage.
This address space region is the managed heap.
The heap also maintains a pointer, which I’ll call NextObjPtr. This pointer indicates where the next object is to be allocated within the heap.
Initially, NextObjPtr is set to the base address of the reserved address space region.
The newobj intermediate language (IL) instruction creates an object.
Many languages (including C#, C++/CLI, and Microsoft Visual Basic) offer a new operator that causes the compiler to emit a newobj instruction into the method’s IL code.
The newobj instruction causes the CLR to perform the following steps:
Calculate the number of bytes required for the type’s (and all of its base type’s) fields.
Add the bytes required for an object’s overhead. Each object has two overhead fields: a type object pointer and a sync block index. For a 32-bit application, each of these fields requires 32 bits, adding 8 bytes to each object. For a 64-bit application, each field is 64 bits, adding 16 bytes to each object.
The CLR then checks that the bytes required to allocate the object are available in the reserved region (committing storage if necessary). If there is enough free space in the managed heap, the object will fit, starting at the address pointed to by NextObjPtr, and these bytes are zeroed out. The type’s constructor is called (passing NextObjPtr for the this parameter), and the newobj IL instruction (or C#’s new operator) returns the address of the object. Just before the address is returned, NextObjPtr is advanced past the object and now points to the address where the next object will be placed in the heap.
Figure 20-1 shows a managed heap consisting of three objects: A, B, and C. If a new object were to be allocated, it would be placed where NextObjPtr points to (immediately after object C).
By contrast, let’s look at how the C-runtime heap allocates memory.
In a C-runtime heap, allocating memory for an object requires walking through a linked list of data structures.
Once a large enough block is found, that block is split, and pointers in the linked-list nodes are modified to keep everything intact.
For the managed heap, allocating an object simply means adding a value to a pointer—this is blazingly fast by comparison.
In fact, allocating an object from the managed heap is nearly as fast as allocating memory from a thread’s stack!
In addition, most heaps (such as the C-runtime heap) allocate objects wherever they find free space.
Therefore, if I create several objects consecutively, it’s quite possible for these objects to be separated by megabytes of address space.
In the managed heap, however, allocating several objects consecutively ensures that the objects are contiguous in memory.
In many applications, objects allocated around the same time tend to have strong relationships to each other and are frequently accessed around the same time.
For example, it’s very common to allocate a FileStream object immediately before a BinaryWriter object is created. Then the application would use the BinaryWriter object, which internally uses the FileStream object.
In a garbage-collected environment, new objects are allocated contiguously in memory, providing performance gains resulting from locality of reference.
Specifically, this means that your process’ working set will be smaller than a similar application running in a non-managed environment.
It’s also likely that the objects that your code is using can all reside in the CPU’s cache.
Your application will access these objects with phenomenal speed because the CPU will be able to perform most of its manipulations without having cache misses that would force slower access to RAM.
So far, it sounds as if the managed heap is far superior to the C-runtime heap because of its simplicity of implementation and speed.
But there’s one little detail you should know about before getting too excited.
The managed heap gains these advantages because it makes one really big assumption: that address space and storage are infinite.
Obviously, this assumption is ridiculous, and the managed heap must employ a mechanism to allow it to make this assumption.
This mechanism is the garbage collector.
Here’s how it works:
When an application calls the new operator to create an object, there might not be enough address space left in the region to allocate to the object.
The heap detects this lack of space by adding the bytes that the object requires to the address in NextObjPtr.
If the resulting value is beyond the end of the address space region, the heap is full, and a garbage collection must be performed.
Important: What I’ve just said is an oversimplification.
In reality, a garbage collection occurs when generation 0 is full.
Some garbage collectors use generations, a mechanism whose sole purpose is to improve performance.
The idea is that newly created objects are part of a young generation and objects created early in the application’s lifecycle are in an old generation.
Objects in Generation 0 are objects that have recently been allocated and have never been examined by the garbage collector algorithm.
Objects that survive a collection are promoted to another generation (such as Generation 1).
Separating objects into generations allows the garbage collector to collect specific generations instead of collecting all of the objects in the managed heap.
I’ll explain generations in more detail later in this chapter.
Until then, it’s easiest for you to think that a garbage collection occurs when the heap is full.
The Garbage Collection Algorithm
The garbage collector checks to see if any objects in the heap are no longer being used by the application.
If such objects exist, the memory used by these objects can be reclaimed.
(If no more memory is available in the heap after a garbage collection,new throws an OutOfMemory-Exception.)
How does the garbage collector know whether the application is using an object?
As you might imagine, this isn’t a simple question to answer.
Every application has a set of roots.
A single root is a storage location containing a memory pointer to a reference type object.
This pointer either refers to an object in the managed heap or is set to null.
For example, a static field (defined within a type) is considered a root.
In addition, any method parameter or local variable is also considered a root.
Only variables that are of a reference type are considered roots; value type variables are never considered roots.
Now, let’s look at a concrete example starting with the following class definition:
internalsealedclassSomeType { private TextWriter m_textWriter; publicSomeType(TextWriter tw) { m_textWriter = tw; } publicvoidWriteBytes(Byte[] bytes) { for (Int32 x = 0; x < bytes.Length; x++) { m_textWriter.Write(bytes[x]); } } }
The first time the WriteBytes method is called, the JIT compiler converts the method’s IL code into native CPU instructions. Let’s say the CLR is running on an x86 CPU, and the JIT compiler compiles the WriteBytes method into the CPU instructions shown in Figure 20-2.
(I added comments on the right to help you understand how the native code maps back to the original source code.)
00000000 push edi // Prolog 00000001 push esi 00000002 push ebx 00000003 mov ebx,ecx // ebx = this (argument) 00000005 mov esi,edx // esi = bytes array (argument) 00000007 xor edi,edi // edi = x (a value type) 00000009 cmp dword ptr [esi+4],0 // compare bytes.Length with 0 0000000d jle 0000002A // if bytes.Length <=0, go to 2a 0000000f mov ecx,dword ptr [ebx+4] // ecx = m_textWriter (field) 00000012 cmp edi,dword ptr [esi+4] // compare x with bytes.Length 00000015 jae 0000002E // if x >= bytes.Length, go to 2e 00000017 movzx edx,byte ptr [esi+edi+8] // edx = bytes[x] 0000001c mov eax,dword ptr [ecx] // eax = m_textWriter’s type object 0000001e call dword ptr [eax+000000BCh] // Call m_textWriter’s write method 00000024 inc edi // x++ 00000025 cmp dword ptr [esi+4],edi // compare bytes.Length with x 00000028 jg 0000000F // if bytes.Length > x, go to f 0000002a pop ebx // Epilog 0000002b pop esi 0000002c pop edi 0000002d ret // return to caller 0000002e call 76B6E337 // Throw IndexOutOfRangeException 00000033 int 3 // Break in debugger Figure 20-2 Native code produced by the JIT compiler with ranges of roots shown
As the JIT compiler produces the native code, it also creates an internal table.
Logically, each entry in the table indicates a range of byte offsets in the method’s native CPU instructions, and for each range, a set of memory addresses and CPU registers that contain roots.
For the WriteBytes method, this table reflects that the EBX register starts being a root at offset 0x00000003, the ESI register starts being a root at offset 0x00000005, and the ECX register starts being a root at offset 0x0000000f.
All three of these registers stop being roots at the end of the loop (offset 0x00000028).
Also note that the EAX register is a root from 0x0000001c to 0x0000001e.
The EDI register is used to hold the Int32 value represented by the variable x in the original source code.
Since Int32 is a value type, the JIT compiler doesn’t consider the EDI register to be a root.
The WriteBytes method is a fairly simple method, and all of the variables that it uses can be enregistered.
A more complex method could use all of the available CPU registers, and some roots would be in memory locations relative to the method’s stack frame.
Also note that on an x86 architecture, the CLR passes the first two arguments to a method via the ECX and EDX registers.
For instance methods, the first argument is the this pointer, which is always passed in the ECX register.
For the WriteBytes method, this is how I know that the this pointer is passed in the ECX register and stored in the EBX register right after the method prolog.
This is also how I know that the bytes argument is passed in the EDX register and stored in the ESI register after the prolog.
If a garbage collection were to start while code was executing at offset 0x00000017 in the WriteBytes method, the garbage collector would know that the objects referred to by the EBX (this argument), ESI (bytes argument), and ECX (the m_textWriter field) registers were all roots and refer to objects in the heap that shouldn’t be considered garbage.
In addition, the garbage collector can walk up the thread’s call stack and determine the roots for all of the calling methods by examining each method’s internal table.
The garbage collector iterates through all the type objects to obtain the set of roots stored in static fields.
When a garbage collection starts, it assumes that all objects in the heap are garbage.
In other words, it is assumed that the thread’s stack contains no variables that refer to objects in the heap, that no CPU registers refer to objects in the heap, and that no static fields refer to objects in the heap.
The garbage collector starts what is called the marking phase of the collection.
This is when the collector walks up the thread’s stack checking all of the roots.
If a root is found to refer to an object, a bit will be turned on in the object’s sync block index field-this is how the object is marked.
For example, the garbage collector might locate a local variable that points to an object in the heap.
Figure 20-3 shows a heap containing several allocated objects, and the application’s roots refer directly to objects A, C, D, and F.
All of these objects are marked.
When marking object D, the garbage collector notices that this object contains a field that refers to object H, causing object H to be marked as well.
The garbage collector continues to walk through all reachable objects recursively.
After a root and the objects referenced by its fields are marked, the garbage collector checks the next root and continues marking objects.
If the garbage collector is going to mark an object that it previously marked, it can stop walking down that path.
This behavior serves two purposes.
First, performance is enhanced significantly because the garbage collector doesn’t walk through a set of objects more than once. Second, infinite loops are prevented if you have any circular linked lists of objects.
Once all of the roots have been checked, the heap contains a set of marked and unmarked objects.
The marked objects are reachable via the application’s code, and the unmarked objects are unreachable.
The unreachable objects are considered garbage, and the memory that they occupy can be reclaimed.
The garbage collector now starts what is called the compact phase of the collection.
This is when the collector traverses the heap linearly looking for contiguous blocks of unmarked (garbage) objects.
If small blocks are found, the garbage collector leaves the blocks alone.
If large free contiguous blocks are found, however, the garbage collector shifts the nongarbage objects down in memory to compact the heap.
Naturally, moving the objects in memory invalidates all variables and CPU registers that contain pointers to the objects.
So the garbage collector must revisit all of the application’s roots and modify them so that each root’s value points to the objects’ new memory location.
In addition, if any object contains a field that refers to another moved object, the garbage collector is responsible for correcting these fields as well. After the heap memory is compacted, the managed heap’s NextObjPtr pointer is set to point to a location just after the last nongarbage object.
Figure 20-4 shows the managed heap after a collection.
As you can see, a garbage collection generates a considerable performance hit, which is the major downside of using a managed heap.
But keep in mind that garbage collections occur only when generation 0 is full, and until then, the managed heap is significantly faster than a C-runtime heap.
Finally, the CLR’s garbage collector offers some optimizations that greatly improve the performance of garbage collection.
I’ll discuss these optimizations later in this chapter, in the “Generations” and “Other Garbage Collector Performance Topics” sections.
As a programmer, you should take away a couple of important points from this discussion.
To start, you no longer have to implement any code to manage the lifetime of objects your application uses.
And notice how the two bugs described at the beginning of this chapter no longer exist.
First, it’s not possible to leak objects because any object not accessible from your application’s roots can be collected at some point. Second, it’s not possible to access an object that is freed because the object won’t be freed if it is reachable, and if it’s not reachable, your application has no way to access it.
Also, since a collection causes memory compaction, it is not possible for managed objects to fragment your process’ virtual address space.
This would sometimes be a severe problem with unmanaged heaps but is no longer an issue when using the managed heap.
Using large objects (discussed later in this chapter) is an exception to this, and fragmentation of the large object heap is possible.
Note:
If garbage collection is so great, you might be wondering why it isn’t in ANSI C++.
The reason is that a garbage collector must be able to identify an application’s roots and must also be able to find all object pointers.
The problem with unmanaged C++ is that it allows casting a pointer from one type to another, and there’s no way to know what a pointer refers to.
In the CLR, the managed heap always knows the actual type of an object and uses the metadata information to determine which members of an object refer to other objects.
The argument provided to the lock keyword must be an object based on a reference type, and is used to define the scope of the lock.
In the example above, the lock scope is limited to this function because no references to the object lockThis exist outside the function.
If such a reference did exist, lock scope would extend to that object.
Strictly speaking, the object provided is used solely to uniquely identify the resource being shared among multiple threads, so it can be an arbitrary class instance.
In practice, however, this object usually represents the resource for which thread synchronization is necessary.
E.G For example, if a container object is to be used by multiple threads, then the container can be passed to lock, and the synchronized code block following the lock would access the container.
As long as other threads locks on the same contain before accessing it, then access to the object is safely synchronized.
Generally, it is best to avoid 1.locking on a public type 2.locking on object instances beyond the control of your application.
E.G For example, lock(this) can be problematic if the instance can be accessed publicly, because code beyond your control may lock on the object as well.
This could create deadlock situations where two or more threads wait for the release of the same object.
Lock on public data type
Locking on a public data type, as opposed to an object, can cause problems for the same reason.
E.G Locking on literal strings is especially risky because literal strings are interned by the common language runtime (CLR).
This means that there is one instance of any given string literal for the entire program, the exact same object represents the literal in all running application domains, on all threads.
As a result, a lock placed on a string with the same contents anywhere in the application process locks all instances of that string in the application.
As a result, it is best to lock a private or protected member that is not interned.
Some classes provide members specifically for locking.
The Array type, for example, provides SyncRoot. Many collection types provide a SyncRoot member as well.
The lock keyword marks a statement block as a critical section by obtaining the mutual-exclusion lock for a given object, executing a statement, and then releasing the lock.
The following example includes a lock statement.
classAccount { decimal balance; private Object thisLock = new Object();
The lock keyword ensures that one thread does not enter a critical section of code while another thread is in the critical section. If another thread tries to enter a locked code, it will wait, block, until the object is released.
The section Threading (C# and Visual Basic) discusses threading.
The lock keyword calls Enter at the start of the block and Exit at the end of the block. A ThreadInterruptedException is thrown if Interrupt interrupts a thread that is waiting to enter a lock statement.
In general, avoid locking on a public type, or instances beyond your code’s control. The common constructs lock (this), lock (typeof (MyType)), and lock (“myLock”) violate this guideline: lock (this) is a problem if the instance can be accessed publicly.
lock (typeof (MyType)) is a problem if MyType is publicly accessible. *lock(“myLock”) is a problem because any other code in the process using the same string, will share the same lock.
Best practice is to define a private object to lock on, or a private static object variable to protect data common to all instances.
You can’t use the await keyword in the body of a lock statement.
staticvoidMain() { ThreadTest b = new ThreadTest(); Thread t = new Thread(b.RunMe); t.Start(); } } // Output: RunMe called
// The following sample uses threads and lock. As long as the lock statement is present, the // statement block is a critical section and balance will never become a negative number. classAccount { private Object thisLock = new Object(); int balance;
Random r = new Random();
publicAccount(int initial) { balance = initial; }
intWithdraw(int amount) {
// This condition never is true unless the lock statement // is commented out. if (balance < 0) { thrownew Exception("Negative Balance"); }
// Comment out the next line to see the effect of leaving out // the lock keyword. lock (thisLock) { if (balance >= amount) { Console.WriteLine("Balance before Withdrawal : " + balance); Console.WriteLine("Amount to Withdraw : -" + amount); balance = balance - amount; Console.WriteLine("Balance after Withdrawal : " + balance); return amount; } else { return0; // transaction rejected } } }
publicvoidDoTransactions() { for (int i = 0; i < 100; i++) { Withdraw(r.Next(1, 100)); } } }
classTest { staticvoidMain() { Thread[] threads = new Thread[10]; Account acc = new Account(1000); for (int i = 0; i < 10; i++) { Thread t = new Thread(new ThreadStart(acc.DoTransactions)); threads[i] = t; } for (int i = 0; i < 10; i++) { threads[i].Start(); } } }
Monitors
Like the lock and SyncLock keywords, monitors prevent blocks of code from simultaneous execution by multiple threads.
The Enter method allows one and only one thread to proceed into the following statements; all other threads are blocked until the executing thread calls Exit.
Using the lock (C#) keyword is generally preferred over using the Monitor class directly, both because
lock or SyncLock is more concise (adj. 简明的,简洁的; ; 简约; 精炼),
And because lock or SyncLock insures that the underlying monitor is released, even if the protected code throws an exception. This is accomplished (by “exit”) with the finally keyword, which executes its associated code block regardless of whether an exception is thrown.
Synchronization Events and Wait Handles
Using a lock or monitor is useful for preventing the simultaneous execution of thread-sensitive blocks of code, but these constructs do not allow one thread to communicate an event to another.
This requires synchronization events, which are objects that have one of two states, signaled and un-signaled, that can be used to activate and suspend threads.
Threads can be suspended by being made to wait on a synchronization event that is unsignaled, and can be activated by changing the event state to signaled.
If a thread attempts to wait on an event that is already signaled, then the thread continues to execute without delay.
There are two kinds of synchronization events: AutoResetEvent
ManualResetEvent
They differ only in that AutoResetEvent changes from signaled to unsignaled automatically any time it activates a thread.
Conversely, a ManualResetEvent allows any number of threads to be activated by its signaled state, and will only revert to an unsignaled state when its Reset method is called.
Threads can be made to wait on events by calling one of the wait methods, such as WaitOne, WaitAny, or WaitAll.
WaitHandle.WaitOne causes the thread to wait until a single event becomes signaled, WaitHandle.WaitAny blocks a thread until one or more indicated events become signaled, *WaitHandle.WaitAll blocks the thread until all of the indicated events become signaled.
An event becomes signaled when its Set method is called.
In the following example, a thread is created and started by the Main function.
The new thread waits on an event using the WaitOne method.
The thread is suspended until the event becomes signaled by the primary thread that is executing the Main function.
Once the event becomes signaled, the auxiliary thread returns.
In this case, because the event is only used for one thread activation, either the AutoResetEvent or ManualResetEvent classes could be used.
A mutex is similar to a monitor; it prevents the simultaneous execution of a block of code by more than one thread at a time. In fact, the name “mutex” is a shortened form of the term “mutually exclusive.”
Unlike monitors, however, a mutex can be used to synchronize threads across processes.
A mutex is represented by the Mutex class.
When used for inter-process synchronization, a mutex is called a named mutex because it is to be used in another application, and therefore it cannot be shared by means of a global or static variable.
It must be given a name so that both applications can access the same mutex object.
Although a mutex can be used for intra-process thread synchronization, using Monitor is generally preferred, because monitors were designed specifically for the .NET Framework and therefore make better use of resources.
In contrast, the Mutex class is a wrapper to a Win32 construct.
While it is more powerful than a monitor, a mutex requires interop transitions that are more computationally expensive than those required by the Monitor class.
For an example of using a mutex, see Mutexes.
Interlocked
For simple operations on integral numeric data types, synchronizing threads can be accomplished with members of the Interlocked class.
You can use the methods of the Interlocked class to prevent problems that can occur when multiple threads attempt to simultaneously update or compare the same value.
The methods of this class let you safely increment, decrement, exchange, and compare values from any thread.
The methods of this class help protect against errors that can occur when the scheduler switches contexts while a thread is updating a variable that can be accessed by other threads, or when two threads are executing concurrently on separate processors.
The members of this class do not throw exceptions.
The Increment and Decrement methods increment or decrement a variable and store the resulting value in a single operation.
On most computers, incrementing a variable is not an atomic operation, requiring the following steps: 1.Load a value from an instance variable into a register. 2.Increment or decrement the value. 3.Store the value in the instance variable.
If you do not use Increment and Decrement, a thread can be preempted after executing the first two steps.
Another thread can then execute all three steps. When the first thread resumes execution, it overwrites the value in the instance variable, and the effect of the increment or decrement performed by the second thread is lost.
The Exchange method atomically exchanges the values of the specified variables.
The CompareExchange method combines two operations: comparing two values and storing a third value in one of the variables, based on the outcome of the comparison.
The compare and exchange operations are performed as an atomic operation.
using System; using System.Threading;
namespaceInterlockedExchange_Example { classMyInterlockedExchangeExampleClass { //0 for false, 1 for true. privatestaticint usingResource = 0;
staticvoidMain() { Thread myThread; Random rnd = new Random();
for(int i = 0; i < numThreads; i++) { myThread = new Thread(new ThreadStart(MyThreadProc)); myThread.Name = String.Format("Thread{0}", i + 1);
//Wait a random amount of time before starting next thread. Thread.Sleep(rnd.Next(0, 1000)); myThread.Start(); } }
privatestaticvoidMyThreadProc() { for(int i = 0; i < numThreadIterations; i++) { UseResource();
//Wait 1 second before next attempt. Thread.Sleep(1000); } }
//A simple method that denies reentrancy. staticboolUseResource() { //0 indicates that the method is not in use. if(0 == Interlocked.Exchange(ref usingResource, 1)) { Console.WriteLine("{0} acquired the lock", Thread.CurrentThread.Name);
//Code to access a resource that is not thread safe would go here.
//Release the lock Interlocked.Exchange(ref usingResource, 0); returntrue; } else { Console.WriteLine(" {0} was denied the lock", Thread.CurrentThread.Name); returnfalse; } }
} }
ReaderWriter Locks
In some cases, you may want to lock a resource only when data is being written and permit multiple clients to simultaneously read data when data is not being updated.
The ReaderWriterLock class enforces exclusive access to a resource while a thread is modifying the resource, but it allows non-exclusive access when reading the resource.
ReaderWriter locks are a useful alternative to exclusive locks, which cause other threads to wait, even when those threads do not need to update data.
Deadlocks
Thread synchronization is invaluable in multithreaded applications, but there is always the danger of creating a deadlock, where multiple threads are waiting for each other and the application comes to a halt.
A deadlock is analogous to a situation in which cars are stopped at a four-way stop and each person is waiting for the other to go.
Avoiding deadlocks is important; the key is careful planning.
You can often predict deadlock situations by diagramming multithreaded applications before you start coding.
Delegates - passing a reference to one method as an argument to another method.
Delegates - allow you to capture a reference to a method and pass it around like any other object, and to call the captured method like any other method.
classDelegateSample { publicdelegateboolComparisonHandler(int first, int second);
publicstaticvoidBubbleSort( int[] items, ComparisonHandler comparisonMethod) { int i; int j; int temp;
if (comparisonMethod == null) { thrownew ArgumentNullException("comparisonMethod"); }
if (items == null) { return; }
for (i = items.Length - 1; i >= 0; i--) { for (j = 1; j <= i; j++) { if (comparisonMethod(items[j - 1], items[j])) { temp = items[j - 1]; items[j - 1] = items[j]; items[j] = temp; } } } }
publicstaticboolGreaterThan(int first, int second) { return first > second; }
publicstaticboolAlphabeticalGreaterThan(int first, int second) { int comparison; comparison = (first.ToString().CompareTo(second.ToString()));
return comparison > 0; }
staticvoidMain() { int i; int[] items = newint[5];
for (i = 0; i < items.Length; i++) { Console.Write("Enter an integer: "); items[i] = int.Parse(Console.ReadLine()); }
Reflection can be used for observing and modifying program execution at runtime.
A reflection-oriented program component can monitor the execution of an enclosure of code and can modify itself according to a desired goal related to that enclosure.
This is typically accomplished by dynamically assigning program code at runtime.
In object oriented programming languages such as Java, reflection allows inspection of classes, interfaces, fields and methods at runtime without knowing the names of the interfaces, fields, methods at compile time.
It also allows instantiation of new objects and invocation of methods.
Reflection can also be used to adapt a given program to different situations dynamically.
For example, consider an application that uses two different classes X and Y interchangeably to perform similar operations.
Without reflection-oriented programming, the application might be hard-coded to call method names of class X and class Y.
However, using the reflection-oriented programming paradigm, the application could be designed and written to utilize reflection in order to invoke methods in classes X and Y without hard-coding method names.
Reflection-oriented programming almost always requires additional knowledge, framework, relational mapping, and object relevance in order to take advantage of more generic code execution.
Reflection is often used as part of software testing, such as for the runtime creation/instantiation of mock objects.
Reflection is also a key strategy for metaprogramming.
In some object-oriented programming languages, such as C# and Java, reflection can be used to override member accessibility rules.
For example, reflection makes it possible to change the value of a field marked “private” in a third-party library’s class.
Implementation
A language supporting reflection provides a number of features available at runtime that would otherwise be difficult to accomplish in a lower-level language.
Some of these features are the abilities to:
Discover and modify source code constructions (such as code blocks, classes, methods, protocols, etc.) as a first-class object at runtime.
Convert a string matching the symbolic name of a class or function into a reference to or invocation of that class or function.
Evaluate a string as if it were a source code statement at runtime.
Create a new interpreter for the language’s bytecode to give a new meaning or purpose for a programming construct.
These features can be implemented in different ways.
In MOO, reflection forms a natural part of everyday programming idiom.
When verbs (methods) are called, various variables such as verb (the name of the verb being called) and this (the object on which the verb is called) are populated to give the context of the call.
Security is typically managed by accessing the caller stack programmatically:
Since callers() is a list of the methods by which the current verb was eventually called, performing tests on callers()[1] (the command invoked by the original user) allows the verb to protect itself against unauthorised use.
Compiled languages rely on their runtime system to provide information about the source code.
A compiled Objective-C executable, for example, records the names of all methods in a block of the executable, providing a table to correspond these with the underlying methods (or selectors for these methods) compiled into the program.
In a compiled language that supports runtime creation of functions, such as Common Lisp, the runtime environment must include a compiler or an interpreter.
Reflection can be implemented for languages not having built-in reflection facilities by using a program transformation system to define automated source code changes.
publicclassProgram { publicstaticvoidMain() { // Derived types can be implicitly converted to // base types Contact contact = new Contact(); PdaItem item = contact;
// ...
// Base types must be cast explicitly to derived types contact = (Contact)item;
// ... } }
The derived type, Contact, is a PdaItem and can be assigned directly to a variable of type PdaItem.
This is known as an implicit conversion because no cast operator is required and the conversion will, on principle, always succeed; it will not throw an exception.
The reverse, however, is not true.
A PdaItem is not necessarily a Contact; it could be an Appointment or some other derived type.
Therefore, casting from the base type to the derived type requires an explicit cast, which at runtime could fail.
To perform an explicit cast, identify the target type within parentheses prior to the original reference.
An implicit conversion to a base class does not instantiate a new instance.
Instead, the same instance is simply referred to as the base type and the capabilities (the accessible members) are those of the base type.
Similarly, casting down from the base class to the derived class simply begins referring to the type more specifically, expanding the available operations.
The restriction is that the actual instantiated type must be an instance of the targeted type (or something derived from it).
A subtlety shown in the Contact.Load() method is worth noting. Developers are often surprised that from code within Contact it is not possible to access the protected ObjectKey of an explicit PdaItem, even though Contact derives from PdaItem. The reason is that a PdaItem could potentially be an Address, and Contact should not be able to access protected members of Address. Therefore, encapsulation prevents Contact from potentially modifying the ObjectKey of an Address. A successful cast to Contact will bypass the restriction as shown. The governing rule is that accessing a protected member from a derived class requires compile-time determination that the protected member is an instance of the derived class (or a class further derived from it).
Extension Methods
We cover interfaces and how to use them with extension methods in the next chapter.
Single Inheritance
C# is a single-inheritance programming language (as is the CIL language to which C# compiles).
For the rare cases that require a multiple-inheritance class structure, one solution is to use aggregation. Instead of one class inheriting from another, one class contains an instance of the other.
Extensions of all other value types with a null value
Reference types
Class types
Ultimate base class of all other types: object
Unicode strings: string
User-defined types of the form class C {…}
Interface types
User-defined types of the form interface I {…}
Array types
Single- and multi-dimensional, for example, int[] and int[,]
Delegate types
User-defined types of the form delegate int D(…)
Difference between value type and reference type
Value Types (directly stores the value associated with variable, less than 16 bytes, stores on ‘stack’)
* All CSharp data types except string and object
* enum
* struct
Signed Integral
sbyte: 8 bits, range from -128 - 127
short: 16 bits, range from -32,768 - 32,767
int : 32 bits, range from -2,147,483,648 - 2,147,483,647
long : 64 bits, range from –9,223,372,036,854,775,808 to 9,223,372,036,854,775,807
Unsigned integral
byte : 8 bits, range from 0 - 255
ushort : 16 bits, range from 0 - 65,535
uint : 32 bits, range from 0 - 4,294,967,295
ulong : 64 bits, range from 0 - 18,446,744,073,709,551,615
Floating point
float : 32 bits, range from 1.5 × 10−45 - 3.4 × 1038, 7-digit precision
double : 64 bits, range from 5.0 × 10−324 - 1.7 × 10308, 15-digit precision
Decimal
decimal : 128 bits, range is at least –7.9 × 10−28 - 7.9 × 1028, with at least 28-digit precision
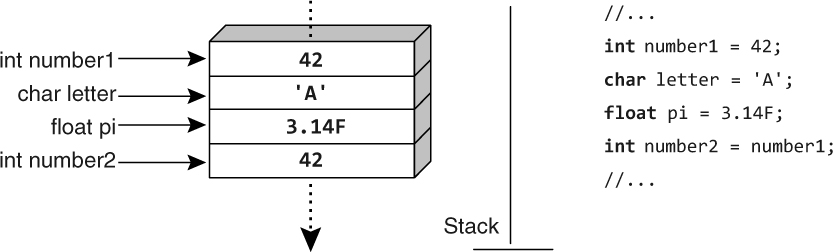
Variables of value types directly contain their values, as shown in Figure 8.1.
The variable name is associated directly with the storage location in memory where the value is stored.
Because of this, when a second variable is assigned the value of an original variable, a copy of the original variable’s value is made to the storage location associated with the second variable.
Two variables never refer to the same storage location (unless one or both are an out or ref parameter, which are, by definition, aliases for another variable).
So, changing the value of the original variable will not affect the value in the second variable, since each variable is associated with a different storage location.
Consequently, changing the value of one value type variable cannot affect the value of any other value type variable.
A value type variable is like a piece of paper that has a number written on it.
If you want to change the number, you can erase it and replace it with a different number.
If you have a second piece of paper, you can copy the number from the first piece of paper, but the two pieces of paper are then independent; erasing and replacing the number on one of them does not change the other.
Similarly, passing an instance of a value type to a method such as Console.WriteLine() will also result in a memory copy from the storage location associated with the argument to the storage location associated with the parameter, and any changes to the parameter variable inside the method will not affect the original value within the caller.
Since value types require a memory copy, they generally should be defined to consume a small amount of memory (typically 16 bytes or less).
Guidelines
DO NOT create value types that consume more than 16 bytes of memory.
Values of value types are often short-lived; often a value is only needed for a portion of an expression or for the activation of a method. In these cases, variables and temporary values of value types can often be stored on the temporary storage pool, often called “the stack.” (Though this is a misnomer; there is no requirement that the temporary pool allocates its storage off the stack, and in fact, as an implementation detail, it frequently chooses to allocate storage out of available registers instead.)
The temporary pool is less costly to clean up than the garbage-collected heap; however, value types tend to be copied more than reference types, and that copying can impose a performance cost of its own. Do not fall into the trap of believing that “value types are faster because they can be allocated on the stack.”
Reference Types (variable stores a reference to the instance, to access the data, runtime get the reference from the variable, then deference it to reach the location in memory that actually contains the data in the memory.
32-bit machine has 4 byte reference, 64-bit machine has 8 byte reference)
string
object
class
interface
delegate
array type
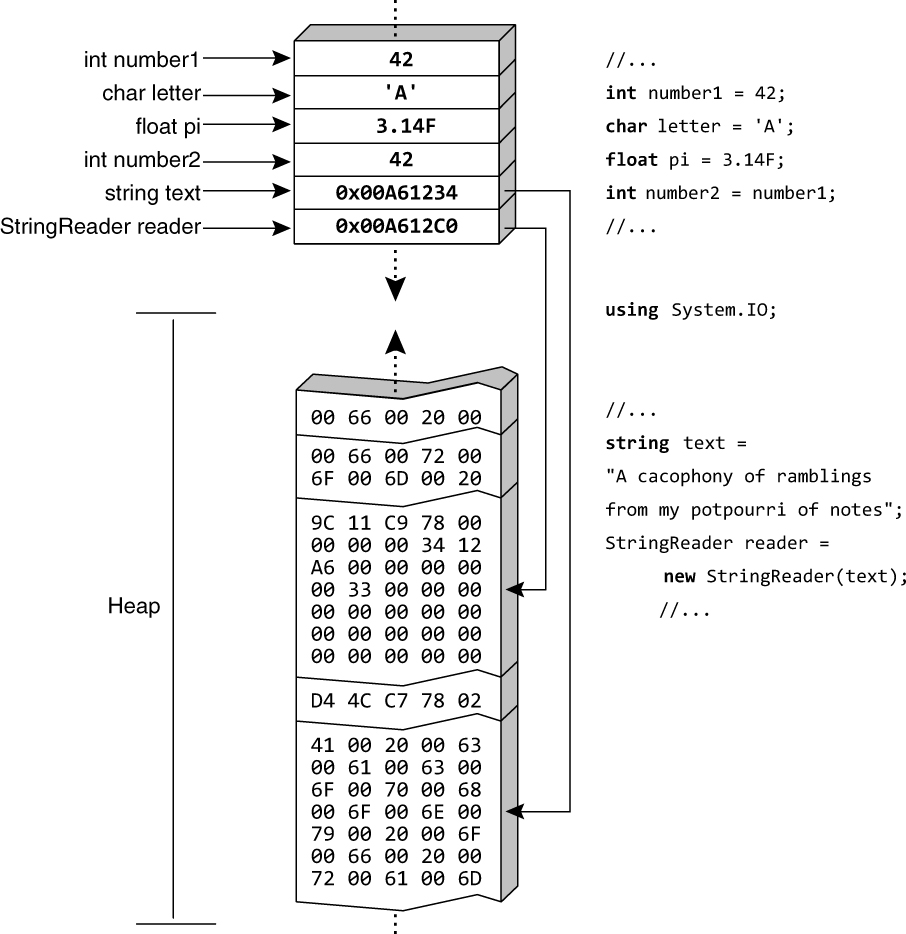
In contrast, the value of a reference type variable is a reference to an instance of an object (see Figure 8.2).
Variables of reference type store the reference (typically implemented as the memory address) where the data for the object instance is located, instead of storing the data directly, as a variable of value type does.
Therefore, to access the data, the runtime will read the reference out of the variable and then dereference it to reach the location in memory that actually contains the data for the instance.
A reference type variable, therefore, has two storage locations associated with it: the storage location directly associated with the variable, and the storage location referred to by the reference that is the value stored in the variable.
A reference type variable is, again, like a piece of paper that always has something written on it.
Imagine, for example, a piece of paper that has a house address written on it: say, “123 Sesame Street, New York City”.
The piece of paper is a variable; the address is a reference to a building.
Neither the paper nor the address written on it is the building, and the location of the paper need not have anything whatsoever to do with the location of the building its contents refer to.
If you make a copy of that reference on another piece of paper, the contents of both pieces of paper refer to the same building.
If you then paint that building green, the building referred to by both pieces of paper can be observed to be green, because the references refer to the same thing.
The storage location directly associated with the variable (or temporary value) is treated no differently than the storage location associated with a value type variable: If the variable is known to be short-lived it is allocated on the short-term storage pool.
The value of a reference type variable is always a reference to a storage location in the garbage-collected heap, or null.
Compared to a variable of value type, which stores the data of the instance directly, accessing the data associated with a reference involves an extra “hop”: First the reference must be dereferenced to find the storage location of the actual data, and then the data can be read or written.
Copying a reference type value only copies the reference, which is small.
(A reference is guaranteed to be no larger than the “bit size” of the processor; a 32-bit machine has 4-byte references, a 64-bit machine has 8-byte references, and so on.) Copying the value of a value type copies all the data, which could be large.
Therefore, there are circumstances in which reference types are more efficient to copy.
This is why the guideline for value types is to ensure that they are never more than 16 bytes or thereabouts; if a value type is more than four times as expensive to copy as a reference, it probably should simply be a reference type.
Since reference types copy only a reference to the data, two different variables can refer to the same data.
Thus, changing the data through one variable will be observed to change the data for the other variable as well.
This happens both for assignment and for method calls.
To continue our previous analogy, if you pass the address of a building to a method, you make a copy of the paper containing the reference and hand the copy to the method.
The method cannot change the contents of the original paper to refer to a different building.
But if the method paints the referred-to building, when the method returns the caller can observe that the building the caller is still referring to is now a different color.
All of the C# “built-in” types, such as bool and decimal, are value types, with the exception of string and object, which are reference types.
Numerous additional value types are provided within the framework. It also is possible for developers to define their own value types.
To define a custom value type, you use a similar syntax as you would to define class and interface types.
The key difference in syntax is that value types use the keyword struct,
Special things about string
changing string through one variable will not be observed to change the changing for the other variable as well.
might same with passing by value which is just copy of the reference. so assigning the string to be another string is really just change the reference to be anther reference.
This leads to 4 memory addresses to be allocated: string1 “Coding”, string2 “Sonata”, string3 [EmptyString] , and the Concatenation between Coding and Sonata
StringBuilder vs String
A string object concatenation operation always creates a new object from the existing string and the new data.
A StringBuilder object maintains a buffer to accommodate the concatenation of new data.
New data is appended to the end of the buffer if room is available;
otherwise, a new, larger buffer is allocated,
data from the original buffer is copied to the new buffer, then the new data is appended to the new buffer.
// Loop over each character. for (int i = 1; i < input.Length - 1; i++) { // See if character is in the table. if (input[i] != input[i - 1]) { // Append to the table and the result. result.Append(input[i]);
} }
return result.ToString(); }
What’s wrong with ‘float’ ?
Not presice
since 32 bit and 7 digit precisions. Have issue that auto rounding.
The result must be 806603.77 but why I get 806603.8 ?
float a = 855000.00f;
float b = 48396.23f;
float res = a - b;
Console.WriteLine(res);
Console.ReadKey();
You should use decimal instead because float has 32-bit with 7 digit precision only that is why the result differs, on other hand decimal has 128-bit with 28-29 digit precision.
decimal a = 855000.00M;
decimal b = 48396.23M;
decimal res = a - b;
Console.WriteLine(res);
Console.ReadKey();
Output: 806603.77
A float (also called System.Single) has a precision equivalent to approximately seven decimal figures.
Your result difference needs eight significant decimal digits. Therefore it is to be expected that there is not enough precision in a float.
ADDITION:
Some extra information: Near 806,000 (806 thousand), a float only has four bits left for the fractional part. So for results it will have to choose between
It chooses the first one since it’s closest to the ideal result. But both of these values are output as “806603.8” when calling ToString() (which Console.WriteLine(float) does call).
A maximum of 7 significant decimal figures are shown with the general ToString call.
To reveal that two floating-point numbers are distinct even though they print the same with the standard formatting, use the format string “R”, for example:
In short, because of the way floating-point numbers represent real numbers, the number you assign to a float is not always the number you get back out. The value you specify is converted to the nearest value that can be represented in scientific notation with a magnitude determined by a base of 2.
In the case of 999999.99, the nearest number that can be represented as a float with the same number of sig figs is 7.6293945 * 217 = 999999.99504, which when rounded to the same sig figs is 1,000,000.00. This may not be the EXACT case, but error like this is inherent in the use of floats.
Do not use floating-point types in situations where the accuracy of the number at a given level of precision is required. Instead, use the decimal type, which will retain the precision of values entered.
From MSDN:
The decimal keyword indicates a 128-bit data type.
Compared to floating-point types, the decimal type has more precision and a smaller range,
which makes it appropriate for financial and monetary calculations.
The approximate range and precision for the decimal type are shown in the following table.
Type
Approximate Range
Precision
.NET Framework type
decimal
(-7.9 x 10^28 to 7.9 x 10^28) / (10^0 to 10^28)
28-29 significant digits
System.Decimal
Alternatively, if dealing with cent or dollar values is multiplying by hundred that way you dealing with the whole cents and do the arithmetic and then scale it back.
Difference between ‘throw’ vs ‘throw exception’.
Yes, there is a difference;
throw ex resets the stack trace (so your errors would appear to originate from HandleException) throw doesn’t - the original offender would be preserved.
throw exception
throw the whole exception stack
throw (exception e)
throw just the current exception.
virtual keyword and Inheritance
class TestClass
{
public class Shape
{
public const double PI = Math.PI;
protected double x, y;
public Shape()
{
}
public Shape(double x, double y)
{
this.x = x;
this.y = y;
}
public virtual double Area()
{
return x * y;
}
}
public class Circle : Shape
{
public Circle(double r) : base(r, 0)
{
}
public override double Area()
{
return PI * x * x;
}
}
class Sphere : Shape
{
public Sphere(double r) : base(r, 0)
{
}
public double Area()
{
return 4 * PI * x * x;
}
}
class Cylinder : Shape
{
public Cylinder(double r, double h) : base(r, h)
{
}
public double Area()
{
return 2 * PI * x * x + 2 * PI * x * y;
}
}
// with `override` on Area(),
// Area of Circle = 28.27
// without `override` on Area(), Shape.Area() hides Circle.Area()
// Area of Circle = 0
// Circle c = new Circle(r);
// with or without `override` on Area(), Circle.Area() excutes
// Area of Circle = 28.27
static void Main()
{
double r = 3.0, h = 5.0;
Shape circle = new Circle(r);
Shape sphere = new Sphere(r);
Shape cylinder = new Cylinder(r, h);
// Display results:
Console.WriteLine("Area of Circle = {0:F2}", circle.Area());
Console.WriteLine("Area of Sphere = {0:F2}", sphere.Area());
Console.WriteLine("Area of Cylinder = {0:F2}", cylinder.Area());
}
}
/*
Output:
Area of Circle = 28.27
Area of Sphere = 0.00
Area of Cylinder = 15.00
*/
Difference between Dictionary and List
Dictionary:
key-value pairs
O(1) lookup
Add - If Count is less than the capacity, this method approaches an O(1) operation. If the capacity must be increased to accommodate the new element, this method becomes an O(n) operation, where n is Count.
Abstract is a class contains anything classes can have plus abstract methods which are signature for methods need to be implemented.
An abstract class is a special kind of class that cannot be instantiated. So the question is why we need a class that cannot be instantiated? An abstract class is only to be sub-classed (inherited from). In other words, it only allows other classes to inherit from it but cannot be instantiated. The advantage is that it enforces certain hierarchies for all the subclasses.
In simple words, it is a kind of contract that forces all the subclasses to carry on the same hierarchies or standards.
Abstract class couldn’t be instantiated, except in the context of instantiating a class that dervies from it.
Interface
An interface is not a class. It is an entity that is defined by the word Interface. An interface has no implementation; it only has the signature or in other words, just the definition of the methods without the body. As one of the similarities to Abstract class, it is a contract that is used to define hierarchies for all subclasses or it defines specific set of methods and their arguments. The main difference between them is that a class can implement more than one interface but can only inherit from one abstract class. Since C# doesn’t support multiple inheritance, interfaces are used to implement multiple inheritance.
staticvoidMain() { // Declare an interface instance. ISampleInterface obj = new ImplementationClass();
// Call the member. obj.SampleMethod(); } }
interface can’t have contructor
Interface only have method declaration without modifiers since everything is public.
Feature
Interface
Abstract class
Multiple inheritance
A class may implement several interfaces.
A class may inherit only one abstract class.
Default implementation
An interface cannot provide any code, just the signature.
An abstract class can provide complete, default code and/or just the details that have to be overridden.
Access Modfiers
An interface cannot have access modifiers for the subs, functions, properties etc everything is assumed as public
An abstract class can contain access modifiers for the subs, functions, properties.
Core VS Peripheral
Interfaces are used to define the peripheral abilities of a class. In other words both Human and Vehicle can inherit from a IMovable interface.
An abstract class defines the core identity of a class and there it is used for objects of the same type.
Homogeneity
If various implementations only share method signatures then it is better to use Interfaces.
If various implementations are of the same kind and use common behaviour or status then abstract class is better to use.
Speed
Requires more time to find the actual method in the corresponding classes.
Fast
Adding functionality (Versioning)
If we add a new method to an Interface then we have to track down all the implementations of the interface and define implementation for the new method.
If we add a new method to an abstract class then we have the option of providing default implementation and therefore all the existing code might work properly.
Fields and Constants
No fields can be defined in interfaces
An abstract class can have fields and constrants defined
Abstract classes also allow for this kind of polymorphism, but with a few caveats:
Classes may inherit from only one base class, so if you want to use abstract classes to provide polymorphism to a group of classes, they must all inherit from that class.
Abstract classes may also provide members that have already been implemented. Therefore, you can ensure a certain amount of identical functionality with an abstract class, but cannot with an interface.
Here are some recommendations to help you to decide whether to use an interface or an abstract class to provide polymorphism for your components.
If you anticipate creating multiple versions of your component, create an abstract class. Abstract classes provide a simple and easy way to version your components. By updating the base class, all inheriting classes are automatically updated with the change. Interfaces, on the other hand, cannot be changed once created. If a new version of an interface is required, you must create a whole new interface.
If the functionality you are creating will be useful across a wide range of disparate objects, use an interface. Abstract classes should be used primarily for objects that are closely related, whereas interfaces are best suited for providing common functionality to unrelated classes.
If you are designing small, concise bits of functionality, use interfaces. If you are designing large functional units, use an abstract class.
If you want to provide common, implemented functionality among all implementations of your component, use an abstract class. Abstract classes allow you to partially implement your class, whereas interfaces contain no implementation for any members.
For the rare cases that require a multiple-inheritance class structure, one solution is to use aggregation; instead of one class inheriting from another, one class contains an instance of the other. Figure 6.2 shows an example of this class structure. Aggregation occurs when the association relationship defines a core part of the containing object. For multiple inheritance, this involves picking one class as the primary base class (PdaItem) and deriving a new class (Contact) from that. The second desired base class (Person) is added as a field in the derived class (Contact). Next, all the nonprivate members on the field (Person) are redefined on the derived class (Contact) which then delegates the calls out to the field (Person). Some code duplication occurs because methods are redeclared; however, this is minimal, since the real method body is implemented only within the aggregated class (Person).
Explicit Interface Implementation
If a class implements two interfaces that contain a member with the same signature, then implementing that member on the class will cause both interfaces to use that member as their implementation.
class Test { static void Main() { SampleClass sc = new SampleClass(); IControl ctrl = (IControl)sc; ISurface srfc = (ISurface)sc;
// The following lines all call the same method. sc.Paint(); ctrl.Paint(); srfc.Paint(); } }
interface IControl { void Paint(); } interface ISurface { void Paint(); } class SampleClass : IControl, ISurface { // Both ISurface.Paint and IControl.Paint call this method. public void Paint() { Console.WriteLine("Paint method in SampleClass"); } }
// Output: // Paint method in SampleClass // Paint method in SampleClass // Paint method in SampleClass
If the two interface members do not perform the same function, however, this can lead to an incorrect implementation of one or both of the interfaces. It is possible to implement an interface member explicitly—creating a class member that is only called through the interface, and is specific to that interface. This is accomplished by naming the class member with the name of the interface and a period. For example:
public class SampleClass : IControl, ISurface { void IControl.Paint() { System.Console.WriteLine("IControl.Paint"); } void ISurface.Paint() { System.Console.WriteLine("ISurface.Paint"); } }
The class member IControl.Paint is only available through the IControl interface, and ISurface.Paint is only available through ISurface. Both method implementations are separate, and neither is available directly on the class. For example:
// Call the Paint methods from Main.
SampleClass obj = new SampleClass(); //obj.Paint(); // Compiler error.
IControl c = (IControl)obj; c.Paint(); // Calls IControl.Paint on SampleClass.
ISurface s = (ISurface)obj; s.Paint(); // Calls ISurface.Paint on SampleClass.
// Output: // IControl.Paint // ISurface.Paint
Explicit implementation is also used to resolve cases where two interfaces each declare different members of the same name such as a property and a method:
interfaceILeft { int P { get;} } interfaceIRight { intP(); }
To implement both interfaces, a class has to use explicit implementation either for the property P, or the method P, or both, to avoid a compiler error. For example:
class Middle : ILeft, IRight { public int P() { return 0; } int ILeft.P { get { return 0; } } }
In the case of ILeft, seems to be problem with modifer needs to be check.
Static Readonly vs Const
So, it appears that constants should be used when it is very unlikely that the value will ever change,
or if no external apps/libs will be using the constant.
Static readonly fields should be used when run-time calculation is required, or if external consumers are a factor.
Very interesting point from the article - “At a high level, constants are obviously dealt with at compile-time, while static readonly fields are set at the time they are evaluated at run-time. The fact that constant values are subsituted by the compiler means that any library/assembly which references the constant value will need to be recompiled if the constant value changes. Libraries referencing a static readonly field will reference the field and not the value, thus they will pick up any change in the field without the need for recompilation”
When you use a const string, the compiler embeds the string’s value at compile-time. Therefore, if you use a const value in a different assembly, then update the original assembly and change the value, the other assembly won’t see the change until you re-compile it.
A static readonly string is a normal field that gets looked up at runtime. Therefore, if the field’s value is changed in a different assembly, the changes will be seen as soon as the assembly is loaded, without recompiling.
This also means that a static readonly string can use non-constant members, such as Environment.UserName or DateTime.Now.ToString(). A const string can only be initialized using other constants or literals. Also, a static readonly string can be set in a static constructor; a const string can only be initialized inline.
Note that a static string can be modified; you should use static readonly instead.
The difference is that the value of a static readonly field is set at run time, and can thus be modified by the containing class, whereas the value of a const field is set to a compile time constant.
In the static readonly case, the containing class is allowed to modify it only
in the variable declaration (through a variable initializer)
in the static constructor (instance constructors, if it’s not static)
static readonly is typically used if the type of the field is not allowed in a const declaration, or when the value is not known at compile time.
Instance readonly fields are also allowed.
Remember that for reference types, in both cases (static and instance) the readonly modifier only prevents you from assigning a new reference to the field. It specifically does not make immutable the object pointed to by the reference.
classProgram { publicstaticreadonly Test test = new Test(); staticvoidMain(string[] args) { test.Name = “Program”; test = new Test(); // Error: A static readonly field cannot be assigned to (except in a static constructor or a variable initializer) } } classTest { publicstring Name; }
On the other hand, if Test were a value type, then assignment to test.Name would be an error.
Constants are immutable values which are known at compile time and do not change for the life of the program.
Only the C# built-in types (excluding System.Object) may be declared as const.
For a list of the built-in types, see Built-In Types Table.
User-defined types, including classes, structs, and arrays, cannot be const.
Use the readonly modifier to create a class, struct, or array that is initialized one time at runtime (for example in a constructor) and thereafter cannot be changed.
C# does not support const methods, properties, or events.
The enum type enables you to define named constants for integral built-in types (for example int, uint, long, and so on). For more information, see enum.
Constants must be initialized as they are declared.
In fact, when the compiler encounters a constant identifier in C# source code (for example, months),
it substitutes the literal value directly into the intermediate language (IL) code that it produces.
Because there is no variable address associated with a constant at run time,
const fields cannot be passed by reference and cannot appear as an l-value in an expression.
Use caution when you refer to constant values defined in other code such as DLLs.
If a new version of the DLL defines a new value for the constant, your program will still hold the old literal value until it is recompiled against the new version.
(constants compile time generate)
Constants can be marked as public, private, protected, internal, protected internal or private protected.
These access modifiers define how users of the class can access the constant. For more information, see Access Modifiers.
Constants are accessed as if they were static fields because the value of the constant is the same for all instances of the type.
You do not use the static keyword to declare them.
Expressions that are not in the class that defines the constant must use the class name, a period, and the name of the constant to access the constant.
Enum
System.Enum is a reference type, but any specific enum type is a value type.
In the same way, System.ValueType is a reference type, but all types inheriting from it (other than System.Enum) are value types.
So if you have an enum Foo and you want a nullable property, you need the property type to be Foo?.
By default, the first enumerator has the value 0, and the value of each successive enumerator is increased by 1.
Access Modifiers
private
The type or member can be accessed only by code in the same class or struct.
private protected
The type or member can be accessed only within its declaring assembly, by code in the same class or in a type that is derived from that class.
protected
The type or member can be accessed only by code in the same class or struct, or in a class that is derived from that class.
The Internal/Friend class contains a protected method.
Select all places from where this method is accessible:
From any class within the same assembly that inherits the original class.
From any class within another assembly that inherits the original class, if the original assembly contains an InternalsVisibleToAttribute that points to this other assembly.
The type or member can be accessed by any code in the same assembly, but not from another assembly.
protected internal
The type or member can be accessed by any code in the same assembly in which it is declared, or from within a derived class in another assembly.
Access from another assembly must take place within a class declaration that derives from the class in which the protected internal element is declared, and it must take place through an instance of the derived class type.
public
The type or member can be accessed by any other code in the same assembly or another assembly that references it.
Default access modifier for classes, methods, members, constructors, delegates and interfaces
The default access for everything in C# is “the most restricted access you could declare for that member”.
The one sort of exception to this is making one part of a property (usually the setter) more restricted than the declared accessibility of the property itself:
publicstring Name { get { ... } privateset { ... } // This isn't the default, have to do it explicitly }
This is what the C# 3.0 specification has to say (section 3.5.1):
Depending on the context in which a member declaration takes place, only certain types of declared accessibility are permitted. Furthermore, when a member declaration does not include any access modifiers, the context in which the declaration takes place determines the default declared accessibility.
Namespaces implicitly have public declared accessibility. No access modifiers are allowed on namespace declarations.
Types declared in compilation units or namespaces can have public or internal declared accessibility and default to internal declared accessibility.
Class members can have any of the five kinds of declared accessibility and default to private declared accessibility. (Note that a type declared as a member of a class can have any of the five kinds of declared accessibility, whereas a type declared as a member of a namespace can have only public or internal declared accessibility.)
Struct members can have public, internal, or private declared accessibility and default to private declared accessibility because structs are implicitly sealed. Struct members introduced in a struct (that is, not inherited by that struct) cannot have protected or protected internal declared accessibility. (Note that a type declared as a member of a struct can have public, internal, or private declared accessibility, whereas a type declared as a member of a namespace can have only public or internal declared accessibility.)
Interface members implicitly have public declared accessibility. No access modifiers are allowed on interface member declarations.
Enumeration members implicitly have public declared accessibility. No access modifiers are allowed on enumeration member declarations.
(Note that nested types would come under the “class members” or “struct members” parts - and therefore default to private visibility.)
Structs
*What is the keyword to define custom type?
“Struct”
Structs share most of the same syntax as classes, although structs are more limited than classes:
Within a struct declaration, fields cannot be initialized unless they are declared as const or static.
A struct cannot declare a default constructor (a constructor without parameters) or a destructor.
Structs can declare constructors that have parameters.
Structs are copied on assignment. When a struct is assigned to a new variable, all the data is copied, and any modification to the new copy does not change the data for the original copy. This is important to remember when working with collections of value types such as Dictionary.
Structs are value types and classes are reference types.
Unlike classes, structs can be instantiated without using a new operator.
A struct cannot inherit from another struct or class, and it cannot be the base of a class. All structs inherit directly from System.ValueType, which inherits from System.Object.
A struct can implement interfaces.
A struct can be used as a nullable type and can be assigned a null value.
While querying data from database, IEnumerable execute select query on server side, load data in-memory on client side and then filter data. Hence does more work and becomes slow.
While querying data from database, IQueryable execute select query on server side with all filters. Hence does less work and becomes fast.
Suitable for
LINQ to Object and LINQ to XML queries.
LINQ to SQL queries.
Custom Query
Doesn’t supports.
Supports using CreateQuery and Execute methods.
Extension method parameter
Extension methods supported in IEnumerable takes functional objects.
Extension methods supported in IEnumerable takes expression objects i.e. expression tree.
When to use
when querying data from in-memory collections like List, Array etc.
when querying data from out-memory (like remote database, service) collections.
Best Uses
In-memory traversal
Paging
Reflection
In computer science, reflection is the ability of a computer program to examine (see type introspection) and modify its own structure and behavior (specifically the values, meta-data, properties and functions) at runtime.
Uses
Reflection can be used for observing and modifying program execution at runtime. A reflection-oriented program component can monitor the execution of an enclosure of code and can modify itself according to a desired goal related to that enclosure. This is typically accomplished by dynamically assigning program code at runtime.
In object oriented programming languages such as Java, reflection allows inspection of classes, interfaces, fields and methods at runtime without knowing the names of the interfaces, fields, methods at compile time. It also allows instantiation of new objects and invocation of methods.
Reflection can also be used to adapt a given program to different situations dynamically. For example, consider an application that uses two different classes X and Y interchangeably to perform similar operations. Without reflection-oriented programming, the application might be hard-coded to call method names of class X and class Y. However, using the reflection-oriented programming paradigm, the application could be designed and written to utilize reflection in order to invoke methods in classes X and Y without hard-coding method names. Reflection-oriented programming almost always requires additional knowledge, framework, relational mapping, and object relevance in order to take advantage of more generic code execution.
Reflection is often used as part of software testing, such as for the runtime creation/instantiation of mock objects.
Reflection is also a key strategy for metaprogramming.
Metaprogramming is a programming technique in which computer programs have the ability to treat programs as their data. It means that a program can be designed to read, generate, analyse or transform other programs, and even modify itself while running. In some cases, this allows programmers to minimize the number of lines of code to express a solution, thus reducing the development time. It also allows programs greater flexibility to efficiently handle new situations without recompilation.
Metaprogramming can be used to move computations from run-time to compile-time, to generate code using compile time computations, and to enable self-modifying code. The language in which the metaprogram is written is called the metalanguage. The language of the programs that are manipulated is called the attribute-oriented programming language. The ability of a programming language to be its own metalanguage is called reflection or “reflexivity”. Reflection is a valuable language feature to facilitate metaprogramming.
In some object-oriented programming languages, such as C# and Java, reflection can be used to override member accessibility rules. For example, reflection makes it possible to change the value of a field marked “private” in a third-party library’s class.
Implementation
The runtime creation/instantiation of mock objects.
Metaprogramming
Reflection can be used to override member accessibility rules.(C#/Java).
Discover and modify source code constructions (such as code blocks, classes, methods, protocols, etc.) as a first-class object at runtime.
Convert a string matching the symbolick name of a class or function into reference to or invocations of that class or function.
Evaluate a string as if it were a source code statement at runtime.
Create a new interpreter for the language’s bytecode to give a new meaning or purpose for a programming construct.
Partial Class(C# 2.0)
Partial classes are portions of a class that the compiler can combine to form a complete class.
Partial classes allow the splitting of a class definition across multiple files
Benifits:
Useful for tools that are generating or modifying code. With partial classes, the tools can work on a file separate from the one the developer is manually coding.
Place any nested classes into their own files. This is in accordance with the coding convention that places each class definition within its own file.
Limition:
Partial classes do not allow extending compiled classes, or classes in other assemblies.
They are only a means of splitting a class implementation across multiple files within the same assembly.
Partial Methods(C# 3.0)
Partial methods allow for a declaration of a method without requiring an implementation.
However, when the optional implementation is included, it can be located in one of the sister partial class definitions, likely in a separate file.
Partial methods allow generated code to call methods that have not necessarily been implemented.
Even though the declarations of partial methods contain no implementation, this code will successfully compile.
If there is no implementation provided for a partial method, no trace of the partial method appears in the CIL. This helps keep code size small while keeping flexibility high.
Limitation
Partial methods are allowed only within partial classes
Partial methods must return void
Similarly, out parameters are not allowed on partial methods.
If a return value is required, ref parameters may be used.
C# Extension Method (C# 3.0)
using System;
publicstaticclassExtensionMethods { publicstaticstringUppercaseFirstLetter(thisstringvalue) { // // Uppercase the first letter in the string. // if (value.Length > 0) { char[] array = value.ToCharArray(); array[0] = char.ToUpper(array[0]); returnnewstring(array); } returnvalue; } }
classProgram { staticvoidMain() { // // Use the string extension method on this value. // stringvalue = "dot net perls"; value = value.UppercaseFirstLetter(); Console.WriteLine(value); } }
LINQ
Rather than add relational or XML-specific features to our programming languages and runtime, with the LINQ project we have taken
a more general approach and are adding general-purpose query facilities to the .NET Framework that apply to all sources of information, not just relational or XML data.
This facility is called .NET Language-Integrated Query (LINQ).
Benfits
We use the term “language-integrated query” to indicate that
“Query”(or LINQ) is an “integrated” feature of the developer’s primary programming languages (for example, Visual C#, Visual Basic).
LINQ allows query expressions to benefit from the rich metadata,
compile-time syntax checking,
static typing
IntelliSense that was previously available only to imperative code.
LINQ also allows a single general purpose declarative query facility to be applied to all in-memory information, not just information from external sources.
Implementation
.NET LINQ defines a set of general purpose standard query operators that allow traversal, filter, and projection operations to be expressed in a direct yet declarative way in any .NET-based programming language.
The standard query operators allow queries to be applied to any IEnumerable-based information source.
LINQ allows third parties to augment the set of standard query operators with new domain-specific operators that are appropriate for the target domain or technology.
More importantly, third parties are also free to replace the standard query operators with their own implementations that provide additional services such as remote evaluation, query translation, optimization, and so on.
By adhering to the conventions of the LINQ pattern, such implementations enjoy the same language integration and tool support as the standard query operators.
The extensibility of the query architecture is used in the LINQ project itself to provide implementations that work over both XML and SQL data.
The query operators over XML (LINQ to XML) use an efficient, easy-to-use, in-memory XML facility to provide XPath/XQuery functionality in the host programming language.
The query operators over relational data (LINQ to SQL) build on the integration of SQL-based schema definitions into the common language runtime (CLR) type system.
This integration provides strong typing over relational data while retaining the expressive power of the relational model and the performance of query evaluation directly in the underlying store.
Delegates - passing a reference to one method as an argument to another method.
Delegates - allow you to capture a reference to a method and pass it around like any other object, and to call the captured method like any other method.
classDelegateSample { publicdelegateboolComparisonHandler(int first, int second);
publicstaticvoidBubbleSort( int[] items, ComparisonHandler comparisonMethod) { int i; int j; int temp;
if (comparisonMethod == null) { thrownew ArgumentNullException("comparisonMethod"); }
if (items == null) { return; }
for (i = items.Length - 1; i >= 0; i--) { for (j = 1; j <= i; j++) { if (comparisonMethod(items[j - 1], items[j])) { temp = items[j - 1]; items[j - 1] = items[j]; items[j] = temp; } } } }
publicstaticboolGreaterThan(int first, int second) { return first > second; }
publicstaticboolAlphabeticalGreaterThan(int first, int second) { int comparison; comparison = (first.ToString().CompareTo(second.ToString()));
return comparison > 0; }
staticvoidMain() { int i; int[] items = newint[5];
for (i = 0; i < items.Length; i++) { Console.Write("Enter an integer: "); items[i] = int.Parse(Console.ReadLine()); }
ref tells the compiler that the object is initialized before entering the function, while out tells the compiler that the object will be initialized inside the function.
So while ref is two-ways, out is out-only.
using System;
classProgram { staticvoidMain() { string value1 = "cat"; // Assign string value SetString1(ref value1); // Pass as reference parameter Console.WriteLine(value1); // Write result
string value2; // Unassigned string SetString2(1, out value2); // Pass as out parameter Console.WriteLine(value2); // Write result }
staticvoidSetString1(refstringvalue) { if (value == "cat") // Test parameter value { Console.WriteLine("Is cat"); } value = "dog"; // Assign parameter to new value }
staticvoidSetString2(int number, outstringvalue) { if (number == 1) // Check int parameter { value = "one"; // Assign out parameter } else { value = "carrot"; // Assign out parameter } } }
yield
using System; using System.Collections.Generic;
publicclassProgram { staticvoidMain() { // // Compute two with the exponent of 30. // foreach (intvalueinComputePower(2, 30)) { Console.Write(value); Console.Write(" "); } Console.WriteLine(); }
publicstatic IEnumerable<int> ComputePower(int number, int exponent) { int exponentNum = 0; int numberResult = 1; // // Continue loop until the exponent count is reached. // while (exponentNum < exponent) { // // Multiply the result. // numberResult *= number; exponentNum++; // // Return the result with yield. // yieldreturn numberResult; } } }
The ASP.NET MVC framework offers the following advantages:
It makes it easier to manage complexity by dividing an application into the model, the view, and the controller.
It does not use view state or serverbased forms. This makes the MVC framework ideal for developers who want full control over the behavior of an application.
It uses a Front Controller pattern that processes Web application requests through a single controller. This enables you to design an application that supports a rich routing infrastructure. For more information, see Front Controller on the MSDN Web site.
It provides better support for testdriven development (TDD).
It works well for Web applications that are supported by large teams of developers and Web designers who need a high degree of control over the application behavior.
ActionResult
ActionResult
Helper Method
Description
ViewResult
View
ViewResult Renders a view as a web page.
PartialViewResult
PartialView
As the name describe PartialViewResult renders the partial view.
RedirectResult
Redirect
When you want to redirect to another action method we will use RedirectResult.
RedirectToRouteResult
RedirectToRoute
Redirect to another action method
ContentResult
Content
Returns a user-defined content type
JsonResult
Json
When you want to return a serialized JSON object
JavascriptResult
JavaScript
Returns a script that can be executed on the client
FileResult
File
Returns a binary output to write to the response
EmptyResult
(None)
returns a null result
What is Partial View? What is ChildAction,cant be call directly, generate PartialView
Partial view is special view which renders a portion of view content. It is just like a user control web form application. Partial can be reusable in multiple views. It helps us to reduce code duplication. In other word a partial view enables us to render a view within the parent view.
@Html.Partial(“PartialViewExample”)
@Html.RenderPartial(“PartialViewExample”)
ChildAction
The ChildActionOnly attribute ensures that an action method can be called only as a child method from within a view. An action method doesn’t need to have this attribute to be used as a child action, but we tend to use this attribute to prevent the action methods from being invoked as a result of a user request. Having defined an action method, we need to create what will be rendered when the action is invoked. Child actions are typically associated with partial views, although this is not compulsory.
[ChildActionOnly] allowing restricted access via code in View.
Phil Haack explains it nicely in this blog post. Basically a child action is a controller action that you could invoke from the view using the Html.Action helper:
@Html.Action("SomeActionName", "SomeController")
This action will then execute and render its output at the specified location in the view. The difference with a Partial is that a partial only includes the specified markup, there’s no other action executing than the main action.
So you basically have the main action which received the request and rendered a view, but from within this view you could render multiple child actions which will go through their independent MVC lifecycle and eventually render the output. And all this will happen in the context of a single HTTP request.
Child actions are useful for creating entire reusable widgets which could be embedded into your views and which go through their independent MVC lifecycle.Child
A view model represents only the data that you want to display on your view/page, whether it be used for static text or for input values (like textboxes and dropdowns).
View Model Validation. FlurentValidation. MVC dataAnnotation.
Razor
Filters in ASP.NET MVC
In ASP.NET MVC, controllers define action methods that usually have a one-to-one relationship with possible user interactions, such as clicking a link or submitting a form.
For example, when the user clicks a link, a request is routed to the designated controller, and the corresponding action method is called.
Sometimes you want to perform logic either before an action method is called or after an action method runs.
To support this, ASP.NET MVC provides filters.
Filters are custom classes that provide both a declarative and programmatic means to add pre-action and post-action behavior to controller action methods.
ASP.NET MVC Filter Types
ASP.NET MVC supports the following types of action filters:
Authorization filters.
These implement IAuthorizationFilter and make security decisions about whether to execute an action method, such as performing authentication or validating properties of the request.
The AuthorizeAttribute class and the RequireHttpsAttribute class are examples of an authorization filter.
Authorization filters run before any other filter.
Action filters.
These implement IActionFilter and wrap the action method execution.
The IActionFilter interface declares two methods: OnActionExecuting and OnActionExecuted.
OnActionExecuting runs before the action method.
OnActionExecuted runs after the action method and can perform additional processing, such as providing extra data to the action method, inspecting the return value, or canceling execution of the action method.
Result filters.
These implement IResultFilter and wrap execution of the ActionResult object.
IResultFilter declares two methods: OnResultExecuting and OnResultExecuted.
OnResultExecuting runs before the ActionResult object is executed.
OnResultExecuted runs after the result and can perform additional processing of the result, such as modifying the HTTP response.
The OutputCacheAttribute class is one example of a result filter.
Exception filters.
These implement IExceptionFilter and execute if there is an unhandled exception thrown during the execution of the ASP.NET MVC pipeline.
Exception filters can be used for tasks such as logging or displaying an error page.
The HandleErrorAttribute class is one example of an exception filter.
The Controller class implements each of the filter interfaces.
You can implement any of the filters for a specific controller by overriding the controller’s On method.
For example, you can override the OnAuthorization method.
The simple controller included in the downloadable sample overrides each of the filters and writes out diagnostic information when each filter runs.
You can implement the following On methods in a controller.
namespaceSystem.ComponentModel.DataAnnotations { // Summary: // Represents an enumeration of the data types associated with data fields and // parameters. publicenum DataType { // Summary: // Represents a custom data type. Custom = 0, // // Summary: // Represents an instant in time, expressed as a date and time of day. DateTime = 1, // // Summary: // Represents a date value. Date = 2, // // Summary: // Represents a time value. Time = 3, // // Summary: // Represents a continuous time during which an object exists. Duration = 4, // // Summary: // Represents a phone number value. PhoneNumber = 5, // // Summary: // Represents a currency value. Currency = 6, // // Summary: // Represents text that is displayed. Text = 7, // // Summary: // Represents an HTML file. Html = 8, // // Summary: // Represents multi-line text. MultilineText = 9, // // Summary: // Represents an e-mail address. EmailAddress = 10, // // Summary: // Represent a password value. Password = 11, // // Summary: // Represents a URL value. Url = 12, // // Summary: // Represents a URL to an image. ImageUrl = 13, // // Summary: // Represents a credit card number. CreditCard = 14, // // Summary: // Represents a postal code. PostalCode = 15, // // Summary: // Represents file upload data type. Upload = 16, } }
for (int i = 2; i < value; i++) { primes[i] = true; }
var limit = Math.Sqrt(value);
for (int i = 2; i < limit; i++) { if (primes[i] == true) { for (int j = i * i; j < value; j += i) { primes[j] = false; } } }
for (int i = 2; i < value; i++) { if (primes[i] == true) { Console.WriteLine(string.Format("{0} is Prime number", i)); } } }
using System;
classProgram { staticvoidMain() { // // Write prime numbers between 0 and 100. // Console.WriteLine("--- Primes between 0 and 100 ---"); for (int i = 0; i < 100; i++) { bool prime = PrimeTool.IsPrime(i); if (prime) { Console.Write("Prime: "); Console.WriteLine(i); } } } }
using System;
publicstaticclassPrimeTool { publicstaticboolIsPrime(int candidate) { // Test whether the parameter is a prime number. if ((candidate & 1) == 0) { if (candidate == 2) { returntrue; } else { returnfalse; } } // Note: // ... This version was changed to test the square. // ... Original version tested against the square root. // ... Also we exclude 1 at the end. for (int i = 3; (i * i) <= candidate; i += 2) { if ((candidate % i) == 0) { returnfalse; } } return candidate != 1; } }
functionisPrime(value) { for(var i = 2; i < value; i++) { if(value % i === 0) { returnfalse; } } return value > 1; }
functionprintPrime(value) { var primes = []; for(var i = 2; i < value; i++) { primes[i] = true; } var limit = Math.sqrt(value); for(var i = 2; i < limit; i++) { if(primes[i] === true) { for(var j = i * i; j < value; j += i) { primes[j] = false; } } } for(var i = 2; i < value; i++) { if(primes[i] === true) { console.log(i + " " + primes[i]); } } }
Stack to Queue
using System.Collections.Generic;
public class Queue<T> { private Stack<T> inbox = new Stack<T>(); private Stack<T> outbox = new Stack<T>();
public void Enqueue(T item) { inbox.Push(item); // Add item. }
public T Dequeue() // Get "oldest" item and remove it { ShiftStacks(); return outbox.Pop(); }
public T Peek() // Get "oldest" item { ShiftStacks(); return outbox.Peek(); }
private void ShiftStacks() // move elements from stackNewest to stackOldest { if (outbox.Count == 0) { while (inbox.Count != 0) { outbox.Push(inbox.Pop()); } } } }
public class QueueV2<T> { private Stack<T> inbox = new Stack<T>(); private Stack<T> outbox = new Stack<T>();
public void Enqueue(T item) { while (inbox.Count != 0) { outbox.Push(inbox.Pop()); }
inbox.Push(item);
while (outbox.Count != 0) { inbox.Push(outbox.Pop()); } }
public T Dequeue() { return inbox.Pop(); }
static void Main(string[] args) { new QueueV2<int>().Enqueue(1); } }
Queue to Stack
using System.Collections.Generic;
namespaceAlgorithms_Csharp.queue { classQueuetoStack { private Queue<int> queue1 = new Queue<int>(); private Queue<int> queue2 = new Queue<int>();
In a nutshell, encapsulation is the hiding of data implementation by restricting access to accessors and mutators。
Abstraction
The best definition of abstraction I’ve ever read is: “An abstraction denotes the essential characteristics of an object that distinguish it from all other kinds of object and thus provide crisply defined conceptual boundaries, relative to the perspective of the viewer.” — G. Booch, Object-Oriented Design With Applications, Benjamin/Cummings, Menlo Park, California, 1991.
Data abstraction is nothing more than the implementation of an object that contains the same essential properties and actions we can find in the original object we are representing.
Inheritance
“Is a” is the inheritance way of object relationship.
Rather than duplicate functionality, inheritance allows you to inherit functionality from another class, called a superclass or base class.
Polymorphism
“Poly” meaning “many” and “morph” meaning “form,” polymorphism refers to the fact that there are multiple implementations of the same signature. And since the same signature cannot be used multiple times within a single class, each implementation of the member signature occurs on a different class.
Polymorphism manifests itself by having multiple methods all with the same name, but slighty different functionality.
There are 2 basic types of polymorphism. Overridding, also called run-time polymorphism, and overloading, which is referred to as compile-time polymorphism. This difference is, for method overloading, the compiler determines which method will be executed, and this decision is made when the code gets compiled. Which method will be used for method overriding is determined at runtime based on the dynamic type of an object.
“Poly” meaning “many” and “morph” meaning “form,” polymorphism refers to the fact that there are multiple implementations of the same signature. And since the same signature cannot be used multiple times within a single class, each implementation of the member signature occurs on a different class. The idea behind polymorphism is that the object itself knows best how to perform a particular operation, and by enforcing common ways to invoke those operations, polymorphism is also a technique for encouraging code reuse when taking advantage of the commonalities. Given multiple types of documents, each document type class knows best how to perform a Print() method for its corresponding document type. Therefore, instead of defining a single print method that includes a switch statement with the special logic to print each document type, with polymorphism you call the Print() method corresponding to the specific type of document you wish to print. For example, calling Print() on a word processing document class behaves according to word processing specifics, and calling the same method on a graphics document class will result in print behavior specific to the graphic. Given the document types, however, all you have to do to print a document is to call Print(), regardless of the type.
Moving the custom print implementation out of a switch statement offers a number of maintenance advantages. First, the implementation appears in the context of each document type’s class rather than in a location far removed; this is in keeping with encapsulation. Second, adding a new document type doesn’t require a change to the switch statement. Instead, all that is necessary is for the new document type class to implement the Print() signature.
Singleton Pattern
In software engineering, the singleton pattern is a design pattern that restricts the instantiation of a class to one object.
Benifits:
This is useful when exactly one object is needed to coordinate actions across the system.
The concept is sometimes generalized to systems that operate more efficiently when only one object exists, or that restrict the instantiation to a certain number of objects.
Implementation
Implementation of a singleton pattern must satisfy the single instance and global access principles.
It requires a mechanism to access the singleton class member without creating a class object and a mechanism to persist the value of class members among class objects.
The singleton pattern is implemented by creating a class with a method that creates a new instance of the class if one does not exist.
If an instance already exists, it simply returns a reference to that object.
To make sure that the object cannot be instantiated any other way, the constructor is made private.
Note the distinction between a simple static instance of a class and a singleton: although a singleton can be implemented as a static instance, it can also be lazily constructed, requiring no memory or resources until needed.
The singleton pattern must be carefully constructed in multi-threaded applications.
If two threads are to execute the creation method at the same time when a singleton does not yet exist, they both must check for an instance of the singleton and then only one should create the new one.
If the programming language has concurrent processing capabilities the method should be constructed to execute as a mutually exclusive operation.
The classic solution to this problem is to use mutual exclusion on the class that indicates that the object is being instantiated.
publicstatic Singleton Instance { get { if (instance == null) { lock (padlock) { if (instance == null) { instance = new Singleton(); } } } return instance; } } }
///<summary> /// The singleton lazy. ///</summary> publicsealedclassSingletonLazy { ///<summary> /// The lazy. ///</summary> privatestaticreadonly Lazy<SingletonLazy> lazy = new Lazy<SingletonLazy>(() => new SingletonLazy());
///<summary> /// Gets the instance. ///</summary> publicstatic SingletonLazy Instance { get { return lazy.Value; } }
///<summary> /// Prevents a default instance of the <see cref="SingletonLazy"/> class from being created. ///</summary> privateSingletonLazy() { } }
DI with IOC
What’s DI ?
What’s IOC container ?
What’s the benfits of IOC container ?
IOC container decides which implement to be put in DI
Which IOC container u using ?
IOC:
In software engineering, inversion of control (IoC) is a design principle in which custom-written portions of a computer program receive the flow of control from a generic framework.
A software architecture with this design inverts control as compared to traditional procedural programming: in traditional programming, the custom code that expresses the purpose of the program calls into reusable libraries to take care of generic tasks, but with inversion of control, it is the framework that calls into the custom, or task-specific, code.
Inversion of control is used to increase modularity of the program and make it extensible,[1] and has applications in object-oriented programming and other programming paradigms.
The term was popularized by Robert C. Martin and Martin Fowler.
The term is related to, but different from, the dependency inversion principle, which concerns itself with decoupling dependencies between high-level and low-level layers through shared abstractions.
Overview
As an example, with traditional programming, the main function of an application might make function calls into a menu library to display a list of available commands and query the user to select one.[2] The library thus would return the chosen option as the value of the function call, and the main function uses this value to execute the associated command. This style was common in text based interfaces. For example, an email client may show a screen with commands to load new mails, answer the current mail, start a new mail, etc., and the program execution would block until the user presses a key to select a command.
With inversion of control, on the other hand, the program would be written using a software framework that knows common behavioral and graphical elements, such as windowing systems, menus, controlling the mouse, and so on. The custom code “fills in the blanks” for the framework, such as supplying a table of menu items and registering a code subroutine for each item, but it is the framework that monitors the user’s actions and invokes the subroutine when a menu item is selected. In the mail client example, the framework could follow both the keyboard and mouse inputs and call the command invoked by the user by either means, and at the same time monitor the network interface to find out if new messages arrive and refresh the screen when some network activity is detected. The same framework could be used as the skeleton for a spreadsheet program or a text editor. Conversely, the framework knows nothing about Web browsers, spreadsheets or text editors; implementing their functionality takes custom code.
Inversion of control carries the strong connotation that the reusable code and the problem-specific code are developed independently even though they operate together in an application. Software frameworks, callbacks, schedulers, event loops and dependency injection are examples of design patterns that follow the inversion of control principle, although the term is most commonly used in the context of object-oriented programming.
Description In traditional programming, the flow of the business logic is determined by objects that are statically bound to one another. With inversion of control, the flow depends on the object graph that is built up during program execution. Such a dynamic flow is made possible by object interactions being defined through abstractions. This run-time binding is achieved by mechanisms such as dependency injection or a service locator. In IoC, the code could also be linked statically during compilation, but finding the code to execute by reading its description from external configuration instead of with a direct reference in the code itself.
In dependency injection, a dependent object or module is coupled to the object it needs at run time. Which particular object will satisfy the dependency during program execution typically cannot be known at compile time using static analysis. While described in terms of object interaction here, the principle can apply to other programming methodologies besides object-oriented programming.
In order for the running program to bind objects to one another, the objects must possess compatible interfaces. For example, class A may delegate behavior to interface I which is implemented by class B; the program instantiates A and B, and then injects B into A.
Benfits Inversion of control serves the following design purposes:
To decouple the execution of a task from implementation.
To focus a module on the task it is designed for. To free modules from assumptions about how other systems do what they do and instead rely on contracts.
To prevent side effects when replacing a module.
Inversion of control is sometimes facetiously referred to as the “Hollywood Principle: Don’t call us, we’ll call you”.
How to implement In object-oriented programming, there are several basic techniques to implement inversion of control. These are:
Using a factory pattern
Using a service locator pattern
Using a dependency injection, for example
A constructor injection
A parameter injection
A setter injection
An interface injection
Using a contextualized lookup
Using template method design pattern
Using strategy design pattern
DI
A dependency is an object that can be used (a service). An injection is the passing of a dependency to a dependent object (a client) that would use it.
The service is made part of the client’s state. Passing the service to the client, rather than allowing a client to build or find the service, is the fundamental requirement of the pattern.
Dependency injection allows a program design to follow the dependency inversion principle.
The client delegates to external code (the injector) the responsibility of providing its dependencies.
The client is not allowed to call the injector code.
It is the injecting code that constructs the services and calls the client to inject them.
This means the client code does not need to know about the injecting code.
The client does not need to know how to construct the services.
The client does not need to know which actual services it is using.
The client only needs to know about the intrinsic interfaces of the services because these define how the client may use the services. This separates the responsibilities of use and construction.
Taxonomy
Inversion of Control (IoC) is more general than DI.
Put simply, IoC means letting other code call you rather than insisting on doing the calling.
An example of IoC without DI is the template pattern. Here polymorphism is achieved through subclassing, that is, inheritance.
Dependency injection implements IoC through composition so is often identical to that of the strategy pattern, but while the strategy pattern is intended for dependencies to be interchangeable throughout an object’s lifetime, in dependency injection it may be that only a single instance of a dependency is used.
This still achieves polymorphism, but through delegation and composition.
Advantages
Dependency injection allows a client the flexibility of being configurable. Only the client’s behavior is fixed. The client may act on anything that supports the intrinsic interface the client expects.
Dependency injection can be used to externalize a system’s configuration details into configuration files allowing the system to be reconfigured without recompilation. Separate configurations can be written for different situations that require different implementations of components. This includes, but is not limited to, testing.
Because dependency injection doesn’t require any change in code behavior it can be applied to legacy code as a refactoring. The result is clients that are more independent and that are easier to unit test in isolation using stubs or mock objects that simulate other objects not under test. This ease of testing is often the first benefit noticed when using dependency injection.
Dependency injection allows a client to remove all knowledge of a concrete implementation that it needs to use. This helps isolate the client from the impact of design changes and defects. It promotes reusability, testability and maintainability.
Reduction of boilerplate code in the application objects since all work to initialize or set up dependencies is handled by a provider component.
Dependency injection allows concurrent or independent development. Two developers can independently develop classes that use each other, while only needing to know the interface the classes will communicate through. Plugins are often developed by third party shops that never even talk to the developers who created the product that uses the plugins.
Dependency Injection decreases coupling between a class and its dependency.
Disadvantages
Dependency injection creates clients that demand configuration details be supplied by construction code. This can be onerous when obvious defaults are available.
Dependency injection can make code difficult to trace (read) because it separates behavior from construction. This means developers must refer to more files to follow how a system performs.
Dependency injection typically requires more upfront development effort since one can not summon into being something right when and where it is needed but must ask that it be injected and then ensure that it is injected.
Dependency injection can cause an explosion of types, especially in languages that have explicit interface types, like Java and C#
Dependency injection forces complexity to move out of classes and into the linkages between classes which might not always be desirable or easily managed.
Ironically, dependency injection can encourage dependence on a dependency injection framework.
Dependency injection is a specific type of IoC using contextualized lookup.
Interface injection comparison
The advantage of interface injection is that dependencies can be completely ignorant of their clients yet can still receive a reference to a new client and, using it, send a reference-to-self back to the client. In this way, the dependencies become injectors. The key is that the injecting method (which could just be a classic setter method) is provided through an interface.
An assembler is still needed to introduce the client and its dependencies. The assembler would take a reference to the client, cast it to the setter interface that sets that dependency, and pass it to that dependency object which would turn around and pass a reference-to-self back to the client.
For interface injection to have value, the dependency must do something in addition to simply passing back a reference to itself. This could be acting as a factory or sub-assembler to resolve other dependencies, thus abstracting some details from the main assembler. It could be reference-counting so that the dependency knows how many clients are using it. If the dependency maintains a collection of clients, it could later inject them all with a different instance of itself.
Interface injection:
This is simply the client publishing a role interface to the setter methods of the client’s dependencies. It can be used to establish how the injector should talk to the client when injecting dependencies.
A database index is a data structure that improves the speed of data retrieval operations on a database table at the cost of additional writes and the use of more storage space to maintain the extra copy of data.
Indexes are used to quickly locate data without having to search every row in a database table every time a database table is accessed.
Indexes can be created using one or more columns of a database table , providing the basis for both rapid random lookups and efficient access of ordered records.
An index is a copy of select columns of data from a table that can be searched very efficiently that also includes a low level disk block address or direct link to the complete row of data it was copied from.
1. With a clustered index the rows are stored physically onthediskinthesameorderastheindex.
There can therefore be only one clustered index.
2. With a non clustered index there is asecond list that has pointers tothe physical rows. You can have many non clustered indexes, although eachnew index will increase thetimeit takes towritenew records.
It is generally faster toreadfroma clustered index if you want toget back all the columns. You donot have to go firsttothe index andthentothe table.
Writing toa table witha clustered index can be slower, if there is a need to rearrange the data.
Clustered
Clustering alters the data block into a certain distinct order to match the index, resulting in the row data being stored in order. Therefore, only one clustered index can be created on a given database table.
Clustered indices can greatly increase overall speed of retrieval, but usually only where the data is accessed sequentially in the same or reverse order of the clustered index, or when a range of items is selected.
Since the physical records are in this sort order on disk, the next row item in the sequence is immediately before or after the last one, and so fewer data block reads are required.
The primary feature of a clustered index is therefore the ordering of the physical data rows in accordance with the index blocks that point to them. Some databases separate the data and index blocks into separate files, others put two completely different data blocks within the same physical file(s).
Tune SQL query performance by avoiding coding loops
Avoid correlated subqueries
Select sparingly
3BNF database
Aviod number-to-character conversions
Be very careful of equality operators
For queries that are executed on a regular basis, try to use procedures.
Avoid using the logical operator OR in a query if possible.
Table should have primary key
Table should have minimum of one clustered index
Table should have appropriate amount of non-clustered index
Non-clustered index should be created on columns of table based on query which is running
Following priority order should be followed when any index is created) WHERE clause, b) JOIN clause, c) ORDER BY clause, d) SELECT clause
Do not to use Views or replace views with original source table
Triggers should not be used if possible, incorporate the logic of trigger in stored procedure
Remove any adhoc queries and use Stored Procedure instead
Check if there is atleast 30% HHD is empty – it improves the performance a bit
If possible move the logic of UDF to SP as well
Remove * from SELECT and use columns which are only necessary in code
Remove any unnecessary joins from table
If there is cursor used in query, see if there is any other way to avoid the usage of this (either by SELECT … INTO or INSERT … INTO, etc)
WITH (NOLOCK)
WITH (NOLOCK) is the equivalent of using READ UNCOMMITED as a transaction isolation level. So, you stand the risk of reading an uncommitted row that is subsequently rolled back, i.e. data that never made it into the database. So, while it can prevent reads being deadlocked by other operations, it comes with a risk. In a banking application with high transaction rates, it’s probably not going to be the right solution to whatever problem you’re trying to solve with it IMHO.
A SELECT in SQL Server will place a shared lock on a table row - and a second SELECT would also require a shared lock, and those are compatible with one another.
So no - one SELECT cannot block another SELECT.
What the WITH (NOLOCK) query hint is used for is to be able to read data that’s in the process of being inserted (by another connection) and that hasn’t been committed yet.
Without that query hint, a SELECT might be blocked reading a table by an ongoing INSERT (or UPDATE) statement that places an exclusive lock on rows (or possibly a whole table), until that operation’s transaction has been committed (or rolled back).
Problem of the WITH (NOLOCK) hint is: you might be reading data rows that aren’t going to be inserted at all, in the end (if the INSERT transaction is rolled back) - so your e.g. report might show data that’s never really been committed to the database.
There’s another query hint that might be useful - WITH (READPAST). This instructs the SELECT command to just skip any rows that it attempts to read and that are locked exclusively. The SELECT will not block, and it will not read any “dirty” un-committed data - but it might skip some rows, e.g. not show all your rows in the table.
Functions are computed values and cannot perform permanent environmental changes to SQL Server (i.e. no INSERT or UPDATE statements allowed).
A Function can be used inline in SQL Statements if it returns a scalar value or can be joined upon if it returns a result set.
Using PIVOT and UNPIVOT
You can use the PIVOT and UNPIVOT relational operators to change a table-valued expression into another table. PIVOT rotates a table-valued expression by turning the unique values from one column in the expression into multiple columns in the output, and performs aggregations where they are required on any remaining column values that are wanted in the final output. UNPIVOT performs the opposite operation to PIVOT by rotating columns of a table-valued expression into column values.
Using DENSE_RANK() OVER (PARTITION BY)
Agile – Collaborate, Integrity, Curious, Rise up asap
Cross-site scripting (XSS) is a type of computer security vulnerability typically found in web applications. XSS enables attackers to inject client-side scripts into web pages viewed by other users. A cross-site scripting vulnerability may be used by attackers to bypass access controls such as the same-origin policy.
Cross-site request forgery, also known as one-click attack or session riding and abbreviated as CSRF (sometimes pronounced sea-surf) or XSRF, is a type of malicious exploit of a website where unauthorized commands are transmitted from a user that the web application trusts. There are many ways in which a malicious website can transmit such commands; specially-crafted image tags, hidden forms, and JavaScript XMLHttpRequests, for example, can all work without the user’s interaction or even knowledge. Unlike cross-site scripting (XSS), which exploits the trust a user has for a particular site, CSRF exploits the trust that a site has in a user’s browser.
Sql injection
ASP.NET MVC Filter for Security
HttpPost and HttpGet 的 attitudes [ ValidateAntiForgeryToken ]
MVC’s anti-forgery support writes a unique value to an HTTP-only cookie and then the same value is written to the form. When the page is submitted, an error is raised if the cookie value doesn’t match the form value.
It’s important to note that the feature prevents cross site request forgeries. That is, a form from another site that posts to your site in an attempt to submit hidden content using an authenticated user’s credentials. The attack involves tricking the logged in user into submitting a form, or by simply programmatically triggering a form when the page loads.
The feature doesn’t prevent any other type of data forgery or tampering based attacks.
To use it, decorate the action method or controller with the ValidateAntiForgeryToken attribute and place a call to @Html.AntiForgeryToken() in the forms posting to the method.
[ ValidateInput ( false )] [ AllowHTML ]
XSS (cross-site scripting) is a security attack where the attacker injects malicious code while doing data entry. Now the good news is that XSS is by default prevented in MVC. So if any one tries to post JavaScript or HTML code he lands with the below error.
Enter image description here
But in real time there are scenarios where HTML has to be allowed, like HTML editors. So for those kind of scenarios you can decorate your action with the below attribute.
[ValidateInput(false)] public ActionResult PostProduct(Product obj) { return View(obj); }
But wait, there is a problem here. The problem is we have allowed HTML on the complete action which can be dangerous. So if we can have more granular control on the field or property level that would really create a neat, tidy and professional solution.
That’s where AllowHTML is useful. You can see in the below code I have decorated “AllowHTML” on the product class property level.
So summarizing “ValidateInput” allows scripts and HTML to be posted on action level while “AllowHTML” is on a more granular level.
I would recommend to use “AllowHTML” more until you are very sure that the whole action needs to be naked.
I would recommend you to read the blog post Preventing XSS Attacks in ASP.NET MVC using ValidateInput and AllowHTML which demonstrates step by step about the importance of these two attributes with an example.
[Bind=(id,column)] Prevent overposting
Garbage Colletion
In computer science , garbage collection ( GC ) is a form of automatic memory management . The garbage collector , or just collector , attempts to reclaim garbage , or memory occupied by objects that are no longer in use by the program . Garbage collection was invented by John McCarthy around 1959 to solve problems in Lisp.
Garbage collection is often portrayed as the opposite of manual memory management , which requires the programmer to specify which objects to deallocate and return to the memory system. However, many systems use a combination of approaches, including other techniques such as stack allocation and region inference . Like other memory management techniques, garbage collection may take a significant proportion of total processing time in a program and can thus have significant influence on performance.
Resources other than memory, such as network sockets , database handles , user interaction windows, and file and device descriptors, are not typically handled by garbage collection. Methods used to manage such resources, particularly destructors , may suffice to manage memory as well, leaving no need for GC. Some GC systems allow such other resources to be associated with a region of memory that, when collected, causes the other resource to be reclaimed; this is called finalization . Finalization may introduce complications limiting its usability, such as intolerable latency between disuse and reclaim of especially limited resources, or a lack of control over which thread performs the work of reclaiming.
Advantages
Garbage collection frees the programmer from manually dealing with memory deallocation. As a result, certain categories of bugs are eliminated or substantially reduced:
Dangling pointer bugs , which occur when a piece of memory is freed while there are still pointers to it, and one of those pointers is dereferenced. By then the memory may have been reassigned to another use, with unpredictable results.
Double free bugs , which occur when the program tries to free a region of memory that has already been freed, and perhaps already been allocated again.
Certain kinds of memory leaks , in which a program fails to free memory occupied by objects that have become unreachable , which can lead to memory exhaustion. (Garbage collection typically does not deal with the unbounded accumulation of data that is reachable, but that will actually not be used by the program.)
Efficient implementations of persistent data structures Some of the bugs addressed by garbage collection can have security implications.
Disadvantages
Typically, garbage collection has certain disadvantages:
Garbage collection consumes computing resources in deciding which memory to free, even though the programmer may have already known this information. The penalty for the convenience of not annotating object lifetime manually in the source code is overhead , which can lead to decreased or uneven performance. Interaction with memory hierarchy effects can make this overhead intolerable in circumstances that are hard to predict or to detect in routine testing.
The moment when the garbage is actually collected can be unpredictable, resulting in stalls scattered throughout a session. Unpredictable stalls can be unacceptable in realtime environments , in transaction processing , or in interactive programs. Incremental, concurrent, and realtime garbage collectors address these problems, with varying tradeoffs.
Nondeterministic GC is incompatible with RAII based management of nonGCed resources. As a result, the need for explicit manual resource management (release/close) for nonGCed resources becomes transitive to composition. That is: in a nondeterministic GC system, if a resource or a resourcelike object requires manual resource management (release/close), and this object is used as ‘part of’ another object, then the composed object will also become a resourcelike object that itself requires manual resource management (release/close).
Generation 1, Generation 2.
IDisposable & using statement
Webservices
SOA
A service-oriented architecture (SOA) is an architectural pattern in computer software design in which application components provide services to other components via a communications protocol, typically over a network. The principles of service-orientation are independent of any vendor, product or technology.
A service is a self-contained unit of functionality, such as retrieving an online bank statement. By that definition, a service is a discretely invokable operation. However, in the Web Services Definition Language (WSDL), a service is an interface definition that may list several discrete services/operations. And elsewhere, the term service is used for a component that is encapsulated behind an interface. This widespread ambiguity is reflected in what follows.
Services can be combined to provide the functionality of a large software application. SOA makes it easier for software components on computers connected over a network to cooperate. Every computer can run any number of services, and each service is built in a way that ensures that the service can exchange information with any other service in the network without human interaction and without the need to make changes to the underlying program itself.
SOAP vs Restful
What’s the difference between SOAP & RESTFUL? Explain why people use RESTFUL instead of SOAP?
“I need to update the local inventory database with the inventory information from multiple suppliers. The suppliers…
provide Web service-based interface. As the application does not have any server side component (the application is a fat client talking directly to the database), is it possible to consume these Web services directly from my application database?”
Do similar questions trouble you? Ever wondered what could be the solution to such problems? To date, we have been familiar with consuming Web services within the application that fetches the data from various databases.
There is a different perspective, where the databases act as the service consumer in contrast to the normal norm of acting as a service provider. Here is how you can invoke a Web service via database stored procedures.
A Web service, in very broad terms, is a method of communication between two applications or electronic devices over the World Wide Web (WWW). Web services are of two kinds: Simple Object Access Protocol (SOAP) and Representational State Transfer (REST).
SOAP defines a standard communication protocol (set of rules) specification for XML-based message exchange. SOAP uses different transport protocols, such as HTTP and SMTP. The standard protocol HTTP makes it easier for SOAP model to tunnel across firewalls and proxies without any modifications to the SOAP protocol. SOAP can sometimes be slower than middleware technologies like CORBA or ICE due to its verbose XML format.
REST describes a set of architectural principles by which data can be transmitted over a standardized interface (such as HTTP). REST does not contain an additional messaging layer and focuses on design rules for creating stateless services. A client can access the resource using the unique URI and a representation of the resource is returned. With each new resource representation, the client is said to transfer state. While accessing RESTful resources with HTTP protocol, the URL of the resource serves as the resource identifier and GET, PUT, DELETE, POST, HEAD and Patch are the standard HTTP operations to be performed on that resource.
REST vs. SOAP
Multiple factors need to be considered when choosing a particular type of Web service, that is between REST and SOAP. The table below breaks down the features of each Web service based on personal experience.
REST
The RESTful Web services are completely stateless. This can be tested by restarting the server and checking if the interactions are able to survive.
Restful services provide a good caching infrastructure over HTTP GET method (for most servers). This can improve the performance, if the data the Web service returns is not altered frequently and not dynamic in nature.
The service producer and service consumer need to have a common understanding of the context as well as the content being passed along as there is no standard set of rules to describe the REST Web services interface.
REST is particularly useful for restricted-profile devices such as mobile and PDAs for which the overhead of additional parameters like headers and other SOAP elements are less.
REST services are easy to integrate with the existing websites and are exposed with XML so the HTML pages can consume the same with ease. There is hardly any need to refactor the existing website architecture. This makes developers more productive and comfortable as they will not have to rewrite everything from scratch and just need to add on the existing functionality.
REST-based implementation is simple compared to SOAP.
SOAP
The Web Services Description Language (WSDL) contains and describes the common set of rules to define the messages, bindings, operations and location of the Web service. WSDL is a sort of formal contract to define the interface that the Web service offers.
SOAP requires less plumbing code than REST services design, (i.e., transactions, security, coordination, addressing, trust, etc.) Most real-world applications are not simple and support complex operations, which require conversational state and contextual information to be maintained. With the SOAP approach, developers need not worry about writing this plumbing code into the application layer themselves.
SOAP Web services (such as JAX-WS) are useful in handling asynchronous processing and invocation.
SOAP supports several protocols and technologies, including WSDL, XSDs, SOAP, WS-Addressing
In a nutshell, when you’re publishing a complex application program interface (API) to the outside world, SOAP will be more useful. But when something with a lower learning curve, and with lightweight and faster results and simple transactions (i.e., CRUD operations) is needed, my vote goes to REST.
Soap Vs Rest SOAP is definitely the heavyweight choice for Web service access. It provides the following advantages when compared to REST:
Language, platform, and transport independent (REST requires use of HTTP) Works well in distributed enterprise environments (REST assumes direct point-to-point communication) Standardized Provides significant pre-build extensibility in the form of the WS* standards Built-in error handling Automation when used with certain language products REST is easier to use for the most part and is more flexible. It has the following advantages when compared to SOAP:
No expensive tools require to interact with the Web service Smaller learning curve Efficient (SOAP uses XML for all messages, REST can use smaller message formats) Fast (no extensive processing required) Closer to other Web technologies in design philosophy
Microservices
avoid single point of failure
Characteristics of Microservices
Componentization via services
Organized around business capabilities
Products not Projects
Smart endoints and dumb pipes
Decentralized Governance
Decentralized Data Management
Infrastructure Automation
Design for failure
Evolutionary Design
Monolith
Microservice
Simplicity
Partial Deployment
Consistency
Availability
Inter-module refactoring
Preserve Modularity
Multiple Platforms
Benefits:
different team on different service , pentatial using different technologies and different data management.
agiligy and quality: isolation of business logic into different services/components, updating any piece doesnt require re-testing.
Reusable of the microservices (web, mobile, b2b, iot)
CI CD is quickly, different react quickly, deploy quickly.
easy to scalable. if certain service suddenly need to process large volume of requests, I can easily just spinning up a few servers for the particular services.
API in front of Micro-services
API connect & gateway (rate limiting, security, monitoring, permissions, version mgmt, etc)
In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system.
The implementation of threads and processes differs between operating systems, but in most cases a thread is a component of a process.
Multiple threads can exist within one process, executing concurrently (one starting before others finish) and share resources such as memory, while different processes do not share these resources.
In particular, the threads of a process share its instructions (executable code) and its context (the values of its variables at any given time).
Multi-thread synchronisation
For all other data types and non thread-safe resources, multithreading can only be safely performed using the constructs in this topic
Lock
The lock (C#) statements can be used to ensure that a block of code runs to completion without interruption by other threads.
Lock on an object
This is accomplished by obtaining a mutual-exclusion lock for a given object for the duration of the code block.
A lock statement is given an object as an argument, and is followed by a code block that is to be executed by only one thread at a time. For example:
publicclassTestThreading { private System.Object lockThis = new System.Object();
The argument provided to the lock keyword must be an object based on a reference type, and is used to define the scope of the lock.
In the example above, the lock scope is limited to this function because no references to the object lockThis exist outside the function.
If such a reference did exist, lock scope would extend to that object.
Strictly speaking, the object provided is used solely to uniquely identify the resource being shared among multiple threads, so it can be an arbitrary class instance.
In practice, however, this object usually represents the resource for which thread synchronization is necessary.
E.G For example, if a container object is to be used by multiple threads, then the container can be passed to lock, and the synchronized code block following the lock would access the container.
As long as other threads locks on the same contain before accessing it, then access to the object is safely synchronized.
Generally, it is best to avoid 1.locking on a public type 2.locking on object instances beyond the control of your application.
E.G For example, lock(this) can be problematic if the instance can be accessed publicly, because code beyond your control may lock on the object as well.
This could create deadlock situations where two or more threads wait for the release of the same object.
Lock on public data type
Locking on a public data type, as opposed to an object, can cause problems for the same reason.
E.G Locking on literal strings is especially risky because literal strings are interned by the common language runtime (CLR).
This means that there is one instance of any given string literal for the entire program, the exact same object represents the literal in all running application domains, on all threads.
As a result, a lock placed on a string with the same contents anywhere in the application process locks all instances of that string in the application.
As a result, it is best to lock a private or protected member that is not interned.
Some classes provide members specifically for locking.
The Array type, for example, provides SyncRoot. Many collection types provide a SyncRoot member as well.
The lock keyword marks a statement block as a critical section by obtaining the mutual-exclusion lock for a given object, executing a statement, and then releasing the lock.
The following example includes a lock statement.
classAccount { decimal balance; private Object thisLock = new Object();
The lock keyword ensures that one thread does not enter a critical section of code while another thread is in the critical section. If another thread tries to enter a locked code, it will wait, block, until the object is released.
The section Threading (C# and Visual Basic) discusses threading.
The lock keyword calls Enter at the start of the block and Exit at the end of the block. A ThreadInterruptedException is thrown if Interrupt interrupts a thread that is waiting to enter a lock statement.
In general, avoid locking on a public type, or instances beyond your code’s control. The common constructs lock (this), lock (typeof (MyType)), and lock (“myLock”) violate this guideline: lock (this) is a problem if the instance can be accessed publicly.
lock (typeof (MyType)) is a problem if MyType is publicly accessible. *lock(“myLock”) is a problem because any other code in the process using the same string, will share the same lock.
Best practice is to define a private object to lock on, or a private static object variable to protect data common to all instances.
You can’t use the await keyword in the body of a lock statement.
staticvoidMain() { ThreadTest b = new ThreadTest(); Thread t = new Thread(b.RunMe); t.Start(); } } // Output: RunMe called
// The following sample uses threads and lock. As long as the lock statement is present, the // statement block is a critical section and balance will never become a negative number. classAccount { private Object thisLock = new Object(); int balance;
Random r = new Random();
publicAccount(int initial) { balance = initial; }
intWithdraw(int amount) {
// This condition never is true unless the lock statement // is commented out. if (balance < 0) { thrownew Exception("Negative Balance"); }
// Comment out the next line to see the effect of leaving out // the lock keyword. lock (thisLock) { if (balance >= amount) { Console.WriteLine("Balance before Withdrawal : " + balance); Console.WriteLine("Amount to Withdraw : -" + amount); balance = balance - amount; Console.WriteLine("Balance after Withdrawal : " + balance); return amount; } else { return0; // transaction rejected } } }
publicvoidDoTransactions() { for (int i = 0; i < 100; i++) { Withdraw(r.Next(1, 100)); } } }
classTest { staticvoidMain() { Thread[] threads = new Thread[10]; Account acc = new Account(1000); for (int i = 0; i < 10; i++) { Thread t = new Thread(new ThreadStart(acc.DoTransactions)); threads[i] = t; } for (int i = 0; i < 10; i++) { threads[i].Start(); } } }
Monitors
Like the lock and SyncLock keywords, monitors prevent blocks of code from simultaneous execution by multiple threads.
The Enter method allows one and only one thread to proceed into the following statements; all other threads are blocked until the executing thread calls Exit.
Using the lock (C#) keyword is generally preferred over using the Monitor class directly, both because
lock or SyncLock is more concise (adj. 简明的,简洁的; ; 简约; 精炼),
And because lock or SyncLock insures that the underlying monitor is released, even if the protected code throws an exception. This is accomplished (by “exit”) with the finally keyword, which executes its associated code block regardless of whether an exception is thrown.
Synchronization Events and Wait Handles
Using a lock or monitor is useful for preventing the simultaneous execution of thread-sensitive blocks of code, but these constructs do not allow one thread to communicate an event to another.
This requires synchronization events, which are objects that have one of two states, signaled and un-signaled, that can be used to activate and suspend threads.
Threads can be suspended by being made to wait on a synchronization event that is unsignaled, and can be activated by changing the event state to signaled.
If a thread attempts to wait on an event that is already signaled, then the thread continues to execute without delay.
There are two kinds of synchronization events: AutoResetEvent
ManualResetEvent
They differ only in that AutoResetEvent changes from signaled to unsignaled automatically any time it activates a thread.
Conversely, a ManualResetEvent allows any number of threads to be activated by its signaled state, and will only revert to an unsignaled state when its Reset method is called.
Threads can be made to wait on events by calling one of the wait methods, such as WaitOne, WaitAny, or WaitAll.
WaitHandle.WaitOne causes the thread to wait until a single event becomes signaled, WaitHandle.WaitAny blocks a thread until one or more indicated events become signaled, *WaitHandle.WaitAll blocks the thread until all of the indicated events become signaled.
An event becomes signaled when its Set method is called.
In the following example, a thread is created and started by the Main function.
The new thread waits on an event using the WaitOne method.
The thread is suspended until the event becomes signaled by the primary thread that is executing the Main function.
Once the event becomes signaled, the auxiliary thread returns.
In this case, because the event is only used for one thread activation, either the AutoResetEvent or ManualResetEvent classes could be used.
A mutex is similar to a monitor; it prevents the simultaneous execution of a block of code by more than one thread at a time. In fact, the name “mutex” is a shortened form of the term “mutually exclusive.”
Unlike monitors, however, a mutex can be used to synchronize threads across processes.
A mutex is represented by the Mutex class.
When used for inter-process synchronization, a mutex is called a named mutex because it is to be used in another application, and therefore it cannot be shared by means of a global or static variable.
It must be given a name so that both applications can access the same mutex object.
Although a mutex can be used for intra-process thread synchronization, using Monitor is generally preferred, because monitors were designed specifically for the .NET Framework and therefore make better use of resources.
In contrast, the Mutex class is a wrapper to a Win32 construct.
While it is more powerful than a monitor, a mutex requires interop transitions that are more computationally expensive than those required by the Monitor class.
For an example of using a mutex, see Mutexes.
Interlocked
For simple operations on integral numeric data types, synchronizing threads can be accomplished with members of the Interlocked class.
You can use the methods of the Interlocked class to prevent problems that can occur when multiple threads attempt to simultaneously update or compare the same value.
The methods of this class let you safely increment, decrement, exchange, and compare values from any thread.
The methods of this class help protect against errors that can occur when the scheduler switches contexts while a thread is updating a variable that can be accessed by other threads, or when two threads are executing concurrently on separate processors.
The members of this class do not throw exceptions.
The Increment and Decrement methods increment or decrement a variable and store the resulting value in a single operation.
On most computers, incrementing a variable is not an atomic operation, requiring the following steps: 1.Load a value from an instance variable into a register. 2.Increment or decrement the value. 3.Store the value in the instance variable.
If you do not use Increment and Decrement, a thread can be preempted after executing the first two steps.
Another thread can then execute all three steps. When the first thread resumes execution, it overwrites the value in the instance variable, and the effect of the increment or decrement performed by the second thread is lost.
The Exchange method atomically exchanges the values of the specified variables.
The CompareExchange method combines two operations: comparing two values and storing a third value in one of the variables, based on the outcome of the comparison.
The compare and exchange operations are performed as an atomic operation.
using System; using System.Threading;
namespaceInterlockedExchange_Example { classMyInterlockedExchangeExampleClass { //0 for false, 1 for true. privatestaticint usingResource = 0;
staticvoidMain() { Thread myThread; Random rnd = new Random();
for(int i = 0; i < numThreads; i++) { myThread = new Thread(new ThreadStart(MyThreadProc)); myThread.Name = String.Format("Thread{0}", i + 1);
//Wait a random amount of time before starting next thread. Thread.Sleep(rnd.Next(0, 1000)); myThread.Start(); } }
privatestaticvoidMyThreadProc() { for(int i = 0; i < numThreadIterations; i++) { UseResource();
//Wait 1 second before next attempt. Thread.Sleep(1000); } }
//A simple method that denies reentrancy. staticboolUseResource() { //0 indicates that the method is not in use. if(0 == Interlocked.Exchange(ref usingResource, 1)) { Console.WriteLine("{0} acquired the lock", Thread.CurrentThread.Name);
//Code to access a resource that is not thread safe would go here.
//Release the lock Interlocked.Exchange(ref usingResource, 0); returntrue; } else { Console.WriteLine(" {0} was denied the lock", Thread.CurrentThread.Name); returnfalse; } }
} }
ReaderWriter Locks
In some cases, you may want to lock a resource only when data is being written and permit multiple clients to simultaneously read data when data is not being updated.
The ReaderWriterLock class enforces exclusive access to a resource while a thread is modifying the resource, but it allows non-exclusive access when reading the resource.
ReaderWriter locks are a useful alternative to exclusive locks, which cause other threads to wait, even when those threads do not need to update data.
Deadlocks
Thread synchronization is invaluable in multithreaded applications, but there is always the danger of creating a deadlock, where multiple threads are waiting for each other and the application comes to a halt.
A deadlock is analogous to a situation in which cars are stopped at a four-way stop and each person is waiting for the other to go.
Avoiding deadlocks is important; the key is careful planning.
You can often predict deadlock situations by diagramming multithreaded applications before you start coding.
Think of semaphores as bouncers at a nightclub. There are a dedicated number of people that are allowed in the club at once. If the club is full no one is allowed to enter, but as soon as one person leaves another person might enter.
It’s simply a way to limit the number of consumers for a specific resource. For example, to limit the number of simultaneous calls to a database in an application.
Here is a very pedagogic example in C# :-)
using System; using System.Collections.Generic; using System.Text; using System.Threading;
publicstaticvoidMain(string[] args) { // Create the semaphore with 3 slots, where 3 are available. Bouncer = new Semaphore(3, 3);
// Open the nightclub. OpenNightclub(); }
publicstaticvoidOpenNightclub() { for (int i = 1; i <= 50; i++) { // Let each guest enter on an own thread. Thread thread = new Thread(new ParameterizedThreadStart(Guest)); thread.Start(i); } }
publicstaticvoidGuest(object args) { // Wait to enter the nightclub (a semaphore to be released). Console.WriteLine("Guest {0} is waiting to entering nightclub.", args); Bouncer.WaitOne();
// Do some dancing. Console.WriteLine("Guest {0} is doing some dancing.", args); Thread.Sleep(500);
// Let one guest out (release one semaphore). Console.WriteLine("Guest {0} is leaving the nightclub.", args); Bouncer.Release(1); } } }
A semaphore with a capacity of one is similar to a Mutex or lock, except that the semaphore has no “owner” — it’s thread-agnostic.
Any thread can call Release on a Semaphore, whereas with Mutex and lock, only the thread that obtained the lock can release it.
More Questions
Backend
if a class derives from 2 interfaces, and these 2 interfaces have the same method name. how to implement this class? hint: explicit interface.
Delegates - passing a reference to one method as an argument to another method.
Delegates - allow you to capture a reference to a method and pass it around like any other object, and to call the captured method like any other method.
What is DTO (data transfer object)? how to convert between domain entity to DTO? do you know any this type of library? (I think interviewer wants to talk about AutoMapper).
A closure is the combination of a function bundled together(enclosed) with references to its surrounding state(the lexical environment).
In other words, a closure gives you access to an outer function’s scope from an inner function.
In JavaScript, closures are created every time a function is created, at function creation time.
To use a closure, simple define a function inside another function and expose it. To expose a function, return it or pass it to another function.
The inner function will have access to the variables in the outer function scope, even after the outer function has returned.
functionmakeFunc() { var name = 'Mozilla'; functiondisplayName() { alert(name); } return displayName; }
var myFunc = makeFunc(); myFunc();
A closure is the combination of a function and the lexical environment within which that function was declared.
The scope that an inner function enjoys continues even after the parent functions have returned.
Lexical scoping
Consider the following:
functioninit() { var name = 'Mozilla'; // name is a local variable created by init functiondisplayName() { // displayName() is the inner function, a closure alert(name); // use variable declared in the parent function } displayName(); } init();
init() creates a local variable called name and a function called displayName(). The displayName() function is an inner function that is defined inside init() and is only available within the body of the init() function. The displayName() function has no local variables of its own. However, because inner functions have access to the variables of outer functions, displayName() can access the variable name declared in the parent function, init().
Closure
Running this code has exactly the same effect as the previous example of the init() function above; what’s different — and interesting — is that the displayName() inner function is returned from the outer function before being executed.
At first glance, it may seem unintuitive that this code still works. In some programming languages, the local variables within a function exist only for the duration of that function’s execution. Once makeFunc() has finished executing, you might expect that the name variable would no longer be accessible. However, because the code still works as expected, this is obviously not the case in JavaScript.
The reason is that functions in JavaScript form closures. A closure is the combination of a function and the lexical environment within which that function was declared. This environment consists of any local variables that were in-scope at the time that the closure was created. In this case, myFunc is a reference to the instance of the function displayName created when makeFunc is run. The instance of displayName maintains a reference to its lexical environment, within which the variable name exists. For this reason, when myFunc is invoked, the variable name remains available for use and “Mozilla” is passed to alert.
functionmakeAdder(x) { returnfunction(y) { return x + y; }; }
var add5 = makeAdder(5); var add10 = makeAdder(10);
functionfade(id) { let dom = document.getElementById(id); level = 1; functionstep() { var h = level.toString(16); dom.style.backgroundColor = '#FFFF' + h + h; if (level < 15) { level += 1; setTimeout(step, 100); } } setTimeout(step, 100); }
Use case
Give objects data privacy
When you use closures for data privacy, the enclosed variables are only in scope within the containing (outer) function.
You can’t get at the data from an outside scope except through the object’s privileged methods . In JavaScript, any exposed method defined within the closure scope is privileged.
In the example above, the .get() method is defined inside the scope of getSecret(), which gives it access to any variables from getSecret(), and makes it a privileged method. In this case, the parameter, secret.
Objects are not the only way to produce data privacy. Closures can also be used to create stateful functions whose return values may be influenced by their internal state, e.g.:
A promise is an object that may produce a single value some time in the future: either a resolved value, or a reason that it’s not resolved (e.g., a network error occurred).
A promise may be in one of 3 possible states: fulfilled, rejected, or pending.
Promise users can attach callbacks to handle the fulfilled value or the reason for rejection.
Promises are eager, meaning that a promise will start doing whatever task you give it as soon as the promise constructor is invoked.
A promise is an object which can be returned synchronously from an asynchronous function. It will be in one of 3 possible states:
Fulfilled: onFulfilled() will be called (e.g., resolve() was called)
Rejected: onRejected() will be called (e.g., reject() was called)
Pending: not yet fulfilled or rejected
A promise is settled if it’s not pending (it has been resolved or rejected).
Once settled, a promise can not be resettled. Calling resolve() or reject() again will have no effect. The immutability of a settled promise is an important feature.
Native JavaScript promises don’t expose promise states. Instead, you’re expected to treat the promise as a black box. Only the function responsible for creating the promise will have knowledge of the promise status, or access to resolve or reject.
Here is a function that returns a promise which will resolve after a specified time delay:
const wait = time => newPromise((resolve) => setTimeout(resolve, time));
A Promise is an object representing the eventual completion or failure of an asynchronous operation.
Since most people are consumers of already-created promises, this guide will explain consumption of returned promises before explaining how to create them.
Essentially, a promise is a returned object to which you attach callbacks, instead of passing callbacks into a function.
let promise = doSomething();
promise.then(successCallback, failureCallback);
doSomething().then(successCallback, failureCallback);
Promises following the spec must follow a specific set of rules:
A promise or “thenable” is an object that supplies a standard-compliant .then() method.
A pending promise may transition into a fulfilled or rejected state.
A fulfilled or rejected promise is settled, and must not transition into any other state.
Once a promise is settled, it must have a value (which may be undefined). That value must not change.
Every promise must supply a .then() method with the following signature:
promise.then(
onFulfilled?: Function,
onRejected?: Function
) => Promise
The .then() method must comply with these rules:
Both onFulfilled() and onRejected() are optional.
If the arguments supplied are not functions, they must be ignored.
onFulfilled() will be called after the promise is fulfilled, with the promise’s value as the first argument.
onRejected() will be called after the promise is rejected, with the reason for rejection as the first argument. The reason may be any valid JavaScript value, but because rejections are essentially synonymous with exceptions, I recommend using Error objects.
Neither onFulfilled() nor onRejected() may be called more than once.
.then() may be called many times on the same promise. In other words, a promise can be used to aggregate callbacks.
.then() must return a new promise, promise2.
If onFulfilled() or onRejected() return a value x, and x is a promise, promise2 will lock in with (assume the same state and value as) x. Otherwise, promise2 will be fulfilled with the value of x.
If either onFulfilled or onRejected throws an exception e, promise2 must be rejected with e as the reason.
If onFulfilled is not a function and promise1 is fulfilled, promise2 must be fulfilled with the same value as promise1.
If onRejected is not a function and promise1 is rejected, promise2 must be rejected with the same reason as promise1.
What is the difference between == and ===?
“==” “equal to” make certain converion
“===” strict equal to same type and same value
JavaScript has both strict and type-converting equality comparison. For strict equality the objects being compared must have the same type and:
Two strings are strictly equal when they have the same sequence of characters, same length, and same characters in corresponding positions.
Two numbers are strictly equal when they are numerically equal (have the same number value). NaN is not equal to anything, including NaN. Positive and negative zeros are equal to one another.
Two Boolean operands are strictly equal if both are true or both are false.
Two objects are strictly equal if they refer to the same Object.
Null and Undefined types are == (but not ===). [I.e. (Null==Undefined) is true but (Null===Undefined) is false]
Spilt all the elements of an array into a new array which contains several arrays.
let oldArray = [1,2,3,4,5,6,7,8,9,10]; let newArray = []; let size = 4; // Size of chunks you are after let j = -1; // This helps us keep track of the child arrays
for (var i = 0; i < oldArray.length; i++) { if (i % size === 0) { j++ } if(!newArray[j]) newArray[j] = []; newArray[j][i % size] = oldArray[i]; } console.log(newArray);
Typescript
Why ‘Typescript’ ?
A superset of ECMAscript that including all ecmascript feature (class, class inheritance) + some proposal feature (Decroator)
You get the type, which also provides with compile time check, intellise.
You get oop feature such interface, abstract (abstraction), access modifiers(Encapsulation), function overloads(Polymorphism), generic for type checking.
Some another feature like Union Type, readonly
test: String|Number
Web
What is gulp?
Automation - gulp is a toolkit that helps you automate painful or time-consuming tasks in your development workflow.
Platform-agnostic - Integrations are built into all major IDEs and people are using gulp with PHP, .NET, Node.js, Java, and other platforms.
Strong Ecosystem - Use npm modules to do anything you want + over 2000 curated plugins for streaming file transformations
Simple - By providing only a minimal API surface, gulp is easy to learn and simple to use
What is webpack ?
webpack is a bundler for modules. The main purpose is to bundle JavaScript files for usage in a browser, yet it is also capable of transforming, bundling, or packaging just about any resource or asset.
TL;DR
Bundles ES Modules, CommonJS and AMD modules (even combined).
Can create a single bundle or multiple chunks that are asynchronously loaded at runtime (to reduce initial loading time).
Dependencies are resolved during compilation, reducing the runtime size.
Loaders can preprocess files while compiling, e.g. TypeScript to JavaScript, Handlebars strings to compiled functions, images to Base64, etc.
Highly modular plugin system to do whatever else your application requires.
Angularjs
what features in NG do you like? why?
MVVM, template
Something about accessing controller object from sub-controller.
Direct access child scope.
What are angularjs component you can declare under angular module?
Table 9-3. The Members of the Module Object
Name
Description
animation(name, factory)
Supports the animation feature, which I describe in Chapter 23.
config(callback)
Registers a function that can be used to configure a module when it is loaded. See the “Working with the Module Life Cycle” section for details.
constant(key, value)
Defines a service that returns a constant value. See the “Working with the Module Life Cycle” section later in this chapter.
controller(name, constructor)
Creates a controller. See Chapter 13 for details.
directive(name, factory)
Creates a directive, which extends the standard HTML vocabulary. See Chapters 15–17.
factory(name, provider)
Creates a service. See Chapter 18 for details and an explanation of how this method differs from the provider and service methods.
filter(name, factory)
Creates a filter that formats data for display to the user. See Chapter 14 for details.
provider(name, type)
Creates a service. See Chapter 18 for details and an explaination of how this method differs from the service and factory methods.
name
Returns the name of the module.
run(callback)
Registers a function that is invoked after AngularJS has loaded and configured all of the modules. See the “Working with the Module Life Cycle” section for details.
service(name, constructor)
Creates a service. See Chapter 18 for details and an explanation of how this method differs from the provider and factory methods.
value(name, value)
Defines a service that returns a constant value; see the “Defining Values” section later in this chapter.
Whiteboard
String Contains
public static bool Contains(string s1, string s2)
{
if (s1 == null)
return s2 == null;
if (s2 == null)
return false;
int i;
for (i = 0; i <= s1.Length - s2.Length; i++)
{
int j;
for (j = 0; j < s2.Length; j++)
{
if (s1[i + j] != s2[j])
{
break;
}
}
if (j == s2.Length)
{
return true;
}
}
return false;
}
Selling tickets
public static string Tickets(int[] peopleInLine)
{
int twentyfiveticket = 0;
int fiftyticket = 0;
foreach (int i in peopleInLine)
{
if (i == 25)
{
a += 1;
}
if (i == 50)
{
b += 1;
a -= 1;
}
if (i == 100)
{
if (b == 0)
{
a -= 3;
}
else
{
b -= 1; a -= 1;
}
}
if (a < 0 || b < 0)
{
return "NO";
}
}
return "YES";
}
Array
Array: 0,4,-3,-2, 90,6,8,9,10,2,1
if there is single value, smaller than previous one and larger than next one, the sequence is 1
the continuous increasing sequence is 0,4 || -3,-2, 90 || 6,8,9,10 || 2 || 1 the longest one is 6,8,9,10, therefore the index is 5.
In a given array, find the first index of the longest continuous increasing sequence.
staticvoidMain(string[] args) { int[] ar = newint[]{0,4,7,12, 90,6,8,9,10,2,1}; // 10 numbers Answer:5 Console.WriteLine("Test Array is {0}",string.Join(",",ar.Select(p=>p.ToString()).ToArray())); Console.WriteLine("The first index of longest increasing sequence is {0}.", GetIndex(ar).ToString()); Console.ReadKey(); }
publicstaticintGetIndex(int[] test) { int maxL = 1, currentL = 1, index = 0;
for (int i = 0; i < test.Length - 1; i++) { if (test[i + 1] > test[i]) currentL++; else { if (currentL > maxL) { maxL = currentL; index = i - maxL + 1; } currentL = 1; } } return index; }
Javascript
Is it possible to make application without using closure ?
Yes
Javascript Prototype Keyword and Prototypal Inheriance.
Javascript: number type: 64bit floating, “double”, 16 digit percisions